Debug dei Workflow¶
Traduzione assistita da IA - scopri di più e suggerisci miglioramenti
Il debug è una competenza fondamentale che può risparmiarvi ore di frustrazione e aiutarvi a diventare sviluppatori Nextflow più efficaci. Nel corso della vostra carriera, specialmente all'inizio, incontrerete bug durante la costruzione e la manutenzione dei vostri workflow. Imparare approcci sistematici al debug vi aiuterà a identificare e risolvere i problemi rapidamente.
Obiettivi di apprendimento¶
In questa side quest, esploreremo tecniche sistematiche di debug per i workflow Nextflow:
- Debug degli errori di sintassi: Utilizzo efficace delle funzionalità dell'IDE e dei messaggi di errore di Nextflow
- Debug dei canali: Diagnosi dei problemi di flusso dati e dei problemi di struttura dei canali
- Debug dei processi: Analisi dei fallimenti di esecuzione e dei problemi di risorse
- Strumenti di debug integrati: Utilizzo della modalità preview di Nextflow, dello stub running e delle directory di lavoro
- Approcci sistematici: Una metodologia in quattro fasi per un debug efficiente
Al termine, avrete una solida metodologia di debug che trasformerà i messaggi di errore frustranti in chiare indicazioni per le soluzioni.
Prerequisiti¶
Prima di affrontare questa side quest, dovreste:
- Aver completato il tutorial Hello Nextflow o un corso equivalente per principianti.
- Essere a proprio agio con i concetti e i meccanismi di base di Nextflow (processi, canali, operatori)
Opzionale: Raccomandiamo di completare prima la side quest IDE Features for Nextflow Development. Questa copre in modo esaustivo le funzionalità dell'IDE che supportano il debug (evidenziazione della sintassi, rilevamento degli errori, ecc.), che utilizzeremo ampiamente qui.
0. Iniziamo¶
Aprite il codespace di formazione¶
Se non l'avete ancora fatto, assicuratevi di aprire l'ambiente di formazione come descritto in Environment Setup.
![]()
Spostatevi nella directory del progetto¶
Spostiamoci nella directory dove si trovano i file per questo tutorial.
Potete impostare VSCode per concentrarsi su questa directory:
Esaminate i materiali¶
Troverete un insieme di workflow di esempio con vari tipi di bug che utilizzeremo per la pratica:
Contenuto della directory
.
├── bad_bash_var.nf
├── bad_channel_shape.nf
├── bad_channel_shape_viewed_debug.nf
├── bad_channel_shape_viewed.nf
├── bad_number_inputs.nf
├── badpractice_syntax.nf
├── bad_resources.nf
├── bad_syntax.nf
├── buggy_workflow.nf
├── data
│ ├── sample_001.fastq.gz
│ ├── sample_002.fastq.gz
│ ├── sample_003.fastq.gz
│ ├── sample_004.fastq.gz
│ ├── sample_005.fastq.gz
│ └── sample_data.csv
├── exhausted.nf
├── invalid_process.nf
├── missing_output.nf
├── missing_software.nf
├── missing_software_with_stub.nf
├── nextflow.config
└── no_such_var.nf
Questi file rappresentano scenari di debug comuni che incontrerete nello sviluppo reale.
Esaminate il compito¶
La vostra sfida è eseguire ogni workflow, identificare gli errori e correggerli.
Per ogni workflow con bug:
- Eseguite il workflow e osservate l'errore
- Analizzate il messaggio di errore: cosa vi sta dicendo Nextflow?
- Localizzate il problema nel codice usando gli indizi forniti
- Correggete il bug e verificate che la soluzione funzioni
- Ripristinate il file prima di passare alla sezione successiva (usate
git checkout <filename>)
Gli esercizi progrediscono da semplici errori di sintassi a problemi di runtime più sottili. Le soluzioni sono discusse inline, ma cercate di risolvere ciascuno da soli prima di leggere avanti.
Lista di controllo per la preparazione¶
Pensate di essere pronti a tuffarvi?
- Comprendo l'obiettivo di questo corso e i suoi prerequisiti
- Il mio codespace è attivo e funzionante
- Ho impostato correttamente la mia directory di lavoro
- Comprendo il compito
Se potete spuntare tutte le caselle, siete pronti a partire.
1. Errori di Sintassi¶
Gli errori di sintassi sono il tipo di errore più comune che incontrerete quando scrivete codice Nextflow. Si verificano quando il codice non è conforme alle regole di sintassi attese del DSL Nextflow. Questi errori impediscono l'esecuzione del vostro workflow, quindi è importante imparare a identificarli e correggerli rapidamente.
1.1. Parentesi graffe mancanti¶
Uno degli errori di sintassi più comuni, e a volte uno dei più complessi da correggere, è quello delle parentesi graffe mancanti o non corrispondenti.
Iniziamo con un esempio pratico.
Eseguite la pipeline¶
Output del comando
Elementi chiave dei messaggi di errore di sintassi:
- File e posizione: Mostra quale file e quale riga/colonna contengono l'errore (
bad_syntax.nf:24:1) - Descrizione dell'errore: Spiega cosa ha trovato il parser che non si aspettava (
Unexpected input: '<EOF>') - Indicatore EOF: Il messaggio
<EOF>(End Of File) indica che il parser ha raggiunto la fine del file mentre si aspettava ancora altro contenuto - un classico segnale di parentesi graffe non chiuse
Esaminate il codice¶
Ora esaminiamo bad_syntax.nf per capire cosa sta causando l'errore:
Per questo esempio abbiamo lasciato un commento per mostrarvi dove si trova l'errore. L'estensione VSCode per Nextflow dovrebbe anche darvi alcuni suggerimenti su cosa potrebbe essere sbagliato, mettendo in rosso la parentesi graffa non corrispondente ed evidenziando la fine prematura del file:
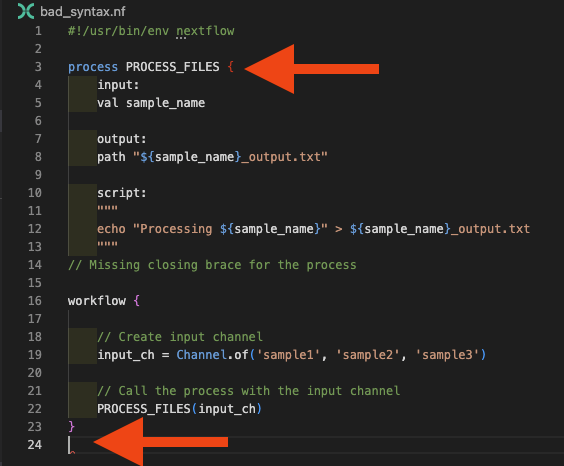
Strategia di debug per gli errori di parentesi graffe:
- Usate la corrispondenza delle parentesi graffe di VS Code (posizionate il cursore accanto a una parentesi graffa)
- Controllate il pannello Problemi per i messaggi relativi alle parentesi graffe
- Assicuratevi che ogni
{di apertura abbia una corrispondente}di chiusura
Correggete il codice¶
Sostituite il commento con la parentesi graffa di chiusura mancante:
Eseguite la pipeline¶
Ora eseguite di nuovo il workflow per confermare che funziona:
Output del comando
1.2. Utilizzo di parole chiave o direttive di processo errate¶
Un altro errore di sintassi comune è una definizione di processo non valida. Questo può accadere se dimenticate di definire i blocchi richiesti o usate direttive errate nella definizione del processo.
Eseguite la pipeline¶
Output del comando
N E X T F L O W ~ version 25.10.2
Launching `invalid_process.nf` [nasty_jepsen] DSL2 - revision: da9758d614
Error invalid_process.nf:3:1: Invalid process definition -- check for missing or out-of-order section labels
│ 3 | process PROCESS_FILES {
│ | ^^^^^^^^^^^^^^^^^^^^^^^
│ 4 | inputs:
│ 5 | val sample_name
│ 6 |
╰ 7 | output:
ERROR ~ Script compilation failed
-- Check '.nextflow.log' file for details
Esaminate il codice¶
Il messaggio di errore indica una "Invalid process definition" e mostra il contesto intorno al problema. Guardando le righe 3-7, possiamo vedere inputs: alla riga 4, che è il problema. Esaminiamo invalid_process.nf:
Guardando la riga 4 nel contesto dell'errore, possiamo individuare il problema: stiamo usando inputs invece della direttiva corretta input. L'estensione VSCode per Nextflow segnalerà anche questo:
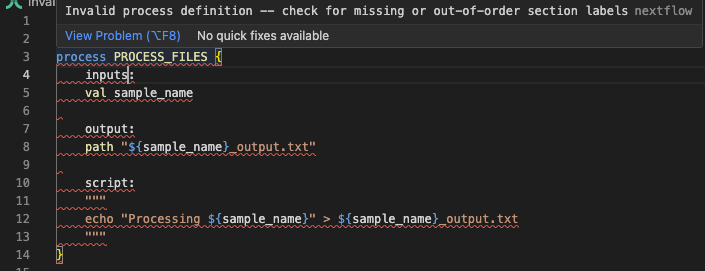
Correggete il codice¶
Sostituite la parola chiave errata con quella corretta facendo riferimento alla documentazione:
Eseguite la pipeline¶
Ora eseguite di nuovo il workflow per confermare che funziona:
Output del comando
1.3. Utilizzo di nomi di variabili errati¶
I nomi delle variabili che usate nei vostri blocchi script devono essere validi, derivati dagli input o dal codice Groovy inserito prima dello script. Ma quando si gestisce la complessità all'inizio dello sviluppo della pipeline, è facile fare errori nella denominazione delle variabili, e Nextflow ve lo farà sapere rapidamente.
Eseguite la pipeline¶
Output del comando
N E X T F L O W ~ version 25.10.2
Launching `no_such_var.nf` [gloomy_meninsky] DSL2 - revision: 0c4d3bc28c
Error no_such_var.nf:17:39: `undefined_var` is not defined
│ 17 | echo "Using undefined variable: ${undefined_var}" >> ${output_pref
╰ | ^^^^^^^^^^^^^
ERROR ~ Script compilation failed
-- Check '.nextflow.log' file for details
L'errore viene rilevato al momento della compilazione e punta direttamente alla variabile non definita alla riga 17, con un accento circonflesso che indica esattamente dove si trova il problema.
Esaminate il codice¶
Esaminiamo no_such_var.nf:
Il messaggio di errore indica che la variabile non è riconosciuta nel template dello script, e lì potete vedere ${undefined_var} usata nel blocco script, ma non definita altrove.
Correggete il codice¶
Se ricevete un errore 'No such variable', potete correggerlo definendo la variabile (correggendo i nomi delle variabili di input o modificando il codice Groovy prima dello script), oppure rimuovendola dal blocco script se non è necessaria:
Eseguite la pipeline¶
Ora eseguite di nuovo il workflow per confermare che funziona:
Output del comando
1.4. Uso errato delle variabili Bash¶
Iniziando con Nextflow, può essere difficile capire la differenza tra le variabili Nextflow (Groovy) e quelle Bash. Questo può generare un'altra forma dell'errore di variabile errata che appare quando si tenta di usare variabili nel contenuto Bash del blocco script.
Eseguite la pipeline¶
Output del comando
N E X T F L O W ~ version 25.10.2
Launching `bad_bash_var.nf` [infallible_mandelbrot] DSL2 - revision: 0853c11080
Error bad_bash_var.nf:13:42: `prefix` is not defined
│ 13 | echo "Processing ${sample_name}" > ${prefix}.txt
╰ | ^^^^^^
ERROR ~ Script compilation failed
-- Check '.nextflow.log' file for details
Esaminate il codice¶
L'errore punta alla riga 13 dove viene usato ${prefix}. Esaminiamo bad_bash_var.nf per vedere cosa sta causando il problema:
| bad_bash_var.nf | |
|---|---|
In questo esempio, stiamo definendo la variabile prefix in Bash, ma in un processo Nextflow la sintassi $ che abbiamo usato per riferirci ad essa (${prefix}) viene interpretata come una variabile Groovy, non Bash. La variabile non esiste nel contesto Groovy, quindi otteniamo un errore 'no such variable'.
Correggete il codice¶
Se volete usare una variabile Bash, dovete fare l'escape del segno del dollaro in questo modo:
| bad_bash_var.nf | |
|---|---|
Questo dice a Nextflow di interpretare questo come una variabile Bash.
Eseguite la pipeline¶
Ora eseguite di nuovo il workflow per confermare che funziona:
Output del comando
Variabili Groovy vs Bash
Per semplici manipolazioni di variabili come la concatenazione di stringhe o le operazioni di prefisso/suffisso, di solito è più leggibile usare variabili Groovy nella sezione script piuttosto che variabili Bash nel blocco script:
Questo approccio evita la necessità di fare l'escape dei segni del dollaro e rende il codice più facile da leggere e mantenere.
1.5. Istruzioni fuori dal blocco workflow¶
L'estensione VSCode per Nextflow evidenzia i problemi con la struttura del codice che causeranno errori. Un esempio comune è la definizione di canali fuori dal blocco workflow {} - questo è ora applicato come errore di sintassi.
Eseguite la pipeline¶
Output del comando
N E X T F L O W ~ version 25.10.2
Launching `badpractice_syntax.nf` [intergalactic_colden] DSL2 - revision: 5e4b291bde
Error badpractice_syntax.nf:3:1: Statements cannot be mixed with script declarations -- move statements into a process or workflow
│ 3 | input_ch = channel.of('sample1', 'sample2', 'sample3')
╰ | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR ~ Script compilation failed
-- Check '.nextflow.log' file for details
Il messaggio di errore indica chiaramente il problema: le istruzioni (come le definizioni di canali) non possono essere mescolate con le dichiarazioni dello script al di fuori di un blocco workflow o processo.
Esaminate il codice¶
Esaminiamo badpractice_syntax.nf per vedere cosa sta causando l'errore:
L'estensione VSCode evidenzierà anche la variabile input_ch come definita fuori dal blocco workflow:
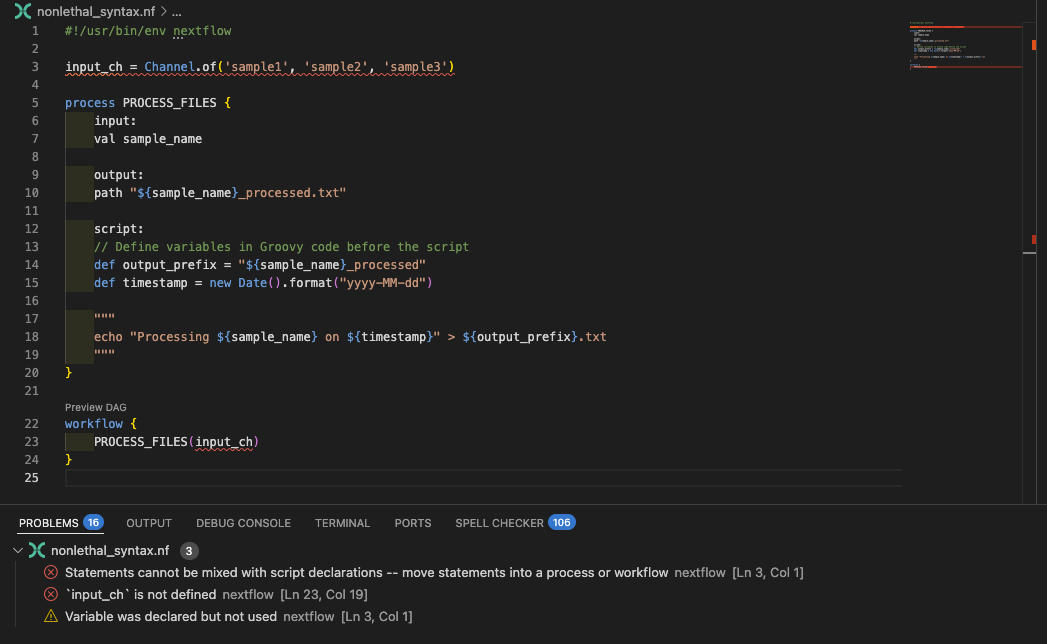
Correggete il codice¶
Spostate la definizione del canale all'interno del blocco workflow:
Eseguite la pipeline¶
Eseguite di nuovo il workflow per confermare che la correzione funziona:
Output del comando
Mantenete i vostri canali di input definiti all'interno del blocco workflow, e in generale seguite qualsiasi altra raccomandazione che l'estensione suggerisce.
Takeaway¶
Potete identificare e correggere sistematicamente gli errori di sintassi usando i messaggi di errore di Nextflow e gli indicatori visivi dell'IDE. Gli errori di sintassi comuni includono parentesi graffe mancanti, parole chiave di processo errate, variabili non definite e uso improprio delle variabili Bash vs. Nextflow. L'estensione VSCode aiuta a rilevare molti di questi prima dell'esecuzione. Con queste competenze di debug della sintassi nel vostro arsenale, sarete in grado di risolvere rapidamente gli errori di sintassi Nextflow più comuni e passare ad affrontare problemi di runtime più complessi.
Cosa c'è dopo?¶
Imparate a fare il debug di errori di struttura dei canali più complessi che si verificano anche quando la sintassi è corretta.
2. Errori di Struttura dei Canali¶
Gli errori di struttura dei canali sono più sottili degli errori di sintassi perché il codice è sintatticamente corretto, ma le forme dei dati non corrispondono a ciò che i processi si aspettano. Nextflow tenterà di eseguire la pipeline, ma potrebbe scoprire che il numero di input non corrisponde a quello atteso e fallire. Questi errori tipicamente appaiono solo a runtime e richiedono una comprensione del flusso di dati attraverso il vostro workflow.
Debug dei canali con .view()
In questa sezione, ricordate che potete usare l'operatore .view() per ispezionare il contenuto dei canali in qualsiasi punto del vostro workflow. Questo è uno degli strumenti di debug più potenti per comprendere i problemi di struttura dei canali. Esploreremo questa tecnica in dettaglio nella sezione 2.4, ma sentitevi liberi di usarla mentre lavorate sugli esempi.
2.1. Numero errato di canali di input¶
Questo errore si verifica quando si passa un numero diverso di canali rispetto a quelli che un processo si aspetta.
Eseguite la pipeline¶
Output del comando
N E X T F L O W ~ version 25.10.2
Launching `bad_number_inputs.nf` [happy_swartz] DSL2 - revision: d83e58dcd3
Error bad_number_inputs.nf:23:5: Incorrect number of call arguments, expected 1 but received 2
│ 23 | PROCESS_FILES(samples_ch, files_ch)
╰ | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR ~ Script compilation failed
-- Check '.nextflow.log' file for details
Esaminate il codice¶
Il messaggio di errore afferma chiaramente che la chiamata si aspettava 1 argomento ma ne ha ricevuti 2, e punta alla riga 23. Esaminiamo bad_number_inputs.nf:
Dovreste vedere la chiamata PROCESS_FILES non corrispondente, che fornisce più canali di input quando il processo ne definisce solo uno. L'estensione VSCode sottolineerà anche la chiamata al processo in rosso e fornirà un messaggio diagnostico quando ci passate sopra con il mouse:
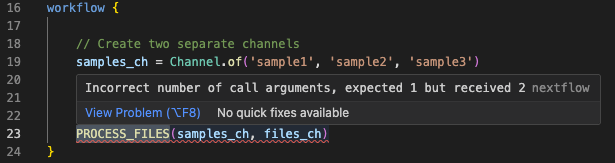
Correggete il codice¶
Per questo esempio specifico, il processo si aspetta un singolo canale e non richiede il secondo canale, quindi possiamo correggerlo passando solo il canale samples_ch:
Eseguite la pipeline¶
Output del comando
Più comunemente rispetto a questo esempio, potreste aggiungere input aggiuntivi a un processo e dimenticare di aggiornare di conseguenza la chiamata nel workflow, il che può portare a questo tipo di errore. Fortunatamente, questo è uno degli errori più facili da capire e correggere, poiché il messaggio di errore è abbastanza chiaro riguardo alla mancata corrispondenza.
2.2. Esaurimento del canale (il processo viene eseguito meno volte del previsto)¶
Alcuni errori di struttura dei canali sono molto più sottili e non producono alcun errore. Probabilmente il più comune di questi riflette una sfida che i nuovi utenti di Nextflow affrontano nel capire che i canali di coda possono esaurirsi e rimanere senza elementi, il che significa che il workflow termina prematuramente.
Eseguite la pipeline¶
Output del comando
N E X T F L O W ~ version 25.10.2
Launching `exhausted.nf` [extravagant_gauss] DSL2 - revision: 08cff7ba2a
executor > local (1)
[bd/f61fff] PROCESS_FILES (1) [100%] 1 of 1 ✔
Questo workflow si completa senza errori, ma elabora solo un singolo campione!
Esaminate il codice¶
Esaminiamo exhausted.nf per vedere se è corretto:
Il processo viene eseguito solo una volta invece di tre perché il canale reference_ch è un canale di coda che si esaurisce dopo la prima esecuzione del processo. Quando un canale si esaurisce, l'intero processo si ferma, anche se altri canali hanno ancora elementi.
Questo è un pattern comune in cui si ha un singolo file di riferimento che deve essere riutilizzato su più campioni. La soluzione è convertire il canale di riferimento in un value channel che può essere riutilizzato indefinitamente.
Correggete il codice¶
Ci sono un paio di modi per affrontare questo problema a seconda di quanti file sono coinvolti.
Opzione 1: Avete un singolo file di riferimento che riutilizzate molto. Potete semplicemente creare un value channel, che può essere usato più e più volte. Ci sono tre modi per farlo:
1a Usate channel.value():
| exhausted.nf (fixed - Option 1a) | |
|---|---|
1b Usate l'operatore first() operator:
| exhausted.nf (fixed - Option 1b) | |
|---|---|
1c. Usate l'operatore collect() operator:
| exhausted.nf (fixed - Option 1c) | |
|---|---|
Opzione 2: In scenari più complessi, forse dove avete più file di riferimento per tutti i campioni nel canale dei campioni, potete usare l'operatore combine per creare un nuovo canale che combina i due canali in tuple:
| exhausted.nf (fixed - Option 2) | |
|---|---|
L'operatore .combine() genera un prodotto cartesiano dei due canali, quindi ogni elemento in reference_ch sarà abbinato a ogni elemento in input_ch. Questo permette al processo di essere eseguito per ogni campione utilizzando comunque il riferimento.
Questo richiede che l'input del processo venga adattato. Nel nostro esempio, l'inizio della definizione del processo dovrebbe essere adattato come segue:
| exhausted.nf (fixed - Option 2) | |
|---|---|
Questo approccio potrebbe non essere adatto in tutte le situazioni.
Eseguite la pipeline¶
Provate una delle correzioni sopra ed eseguite di nuovo il workflow:
Output del comando
Ora dovreste vedere tutti e tre i campioni elaborati invece di uno solo.
2.3. Struttura del contenuto del canale errata¶
Quando i workflow raggiungono un certo livello di complessità, può essere un po' difficile tenere traccia delle strutture interne di ogni canale, e le persone comunemente generano mancate corrispondenze tra ciò che il processo si aspetta e ciò che il canale contiene effettivamente. Questo è più sottile del problema discusso in precedenza, dove il numero di canali era errato. In questo caso, potete avere il numero corretto di canali di input, ma la struttura interna di uno o più di quei canali non corrisponde a ciò che il processo si aspetta.
Eseguite la pipeline¶
Output del comando
Launching `bad_channel_shape.nf` [hopeful_pare] DSL2 - revision: ffd66071a1
executor > local (3)
executor > local (3)
[3f/c2dcb3] PROCESS_FILES (3) [ 0%] 0 of 3 ✘
ERROR ~ Error executing process > 'PROCESS_FILES (1)'
Caused by:
Missing output file(s) `[sample1, file1.txt]_output.txt` expected by process `PROCESS_FILES (1)`
Command executed:
echo "Processing [sample1, file1.txt]" > [sample1, file1.txt]_output.txt
Command exit status:
0
Command output:
(empty)
Work dir:
/workspaces/training/side-quests/debugging/work/d6/1fb69d1d93300bbc9d42f1875b981e
Tip: when you have fixed the problem you can continue the execution adding the option `-resume` to the run command line
-- Check '.nextflow.log' file for details
Esaminate il codice¶
Le parentesi quadre nel messaggio di errore forniscono l'indizio qui - il processo sta trattando la tupla come un singolo valore, il che non è quello che vogliamo. Esaminiamo bad_channel_shape.nf:
Potete vedere che stiamo generando un canale composto da tuple: ['sample1', 'file1.txt'], ma il processo si aspetta un singolo valore, val sample_name. Il comando eseguito mostra che il processo sta cercando di creare un file chiamato [sample3, file3.txt]_output.txt, che non è l'output previsto.
Correggete il codice¶
Per correggere questo, se il processo richiede entrambi gli input potremmo adattare il processo per accettare una tupla:
| bad_channel_shape.nf | |
|---|---|
Eseguite la pipeline¶
Scegliete una delle soluzioni e rieseguite il workflow:
Output del comando
2.4. Tecniche di debug dei canali¶
Utilizzo di .view() per l'ispezione dei canali¶
Lo strumento di debug più potente per i canali è l'operatore .view(). Con .view(), potete capire la forma dei vostri canali in tutte le fasi per aiutare con il debug.
Eseguite la pipeline¶
Eseguite bad_channel_shape_viewed.nf per vedere questo in azione:
Output del comando
N E X T F L O W ~ version 25.10.2
Launching `bad_channel_shape_viewed.nf` [maniac_poisson] DSL2 - revision: b4f24dc9da
executor > local (3)
[c0/db76b3] PROCESS_FILES (3) [100%] 3 of 3 ✔
Channel content: [sample1, file1.txt]
Channel content: [sample2, file2.txt]
Channel content: [sample3, file3.txt]
After mapping: sample1
After mapping: sample2
After mapping: sample3
Esaminate il codice¶
Esaminiamo bad_channel_shape_viewed.nf per vedere come viene usato .view():
Correggete il codice¶
Per evitare di dover usare operazioni .view() eccessivamente in futuro per capire il contenuto dei canali, è consigliabile aggiungere alcuni commenti di aiuto:
| bad_channel_shape_viewed.nf (with comments) | |
|---|---|
Questo diventerà più importante man mano che i vostri workflow crescono in complessità e la struttura dei canali diventa più opaca.
Eseguite la pipeline¶
Output del comando
N E X T F L O W ~ version 25.10.2
Launching `bad_channel_shape_viewed.nf` [marvelous_koch] DSL2 - revision: 03e79cdbad
executor > local (3)
[ff/d67cec] PROCESS_FILES (2) | 3 of 3 ✔
Channel content: [sample1, file1.txt]
Channel content: [sample2, file2.txt]
Channel content: [sample3, file3.txt]
After mapping: sample1
After mapping: sample2
After mapping: sample3
Takeaway¶
Molti errori di struttura dei canali possono essere creati con sintassi Nextflow valida. Potete fare il debug degli errori di struttura dei canali comprendendo il flusso di dati, usando gli operatori .view() per l'ispezione e riconoscendo i pattern dei messaggi di errore come le parentesi quadre che indicano strutture di tuple inattese.
Cosa c'è dopo?¶
Imparate gli errori creati dalle definizioni di processo.
3. Errori di Struttura dei Processi¶
La maggior parte degli errori che incontrerete relativi ai processi sarà legata a errori nella formazione del comando, o a problemi relativi al software sottostante. Detto questo, analogamente ai problemi dei canali sopra, potete fare errori nella definizione del processo che non si qualificano come errori di sintassi, ma che causeranno errori a runtime.
3.1. File di output mancanti¶
Un errore comune quando si scrivono processi è fare qualcosa che genera una mancata corrispondenza tra ciò che il processo si aspetta e ciò che viene generato.
Eseguite la pipeline¶
Output del comando
N E X T F L O W ~ version 25.10.2
Launching `missing_output.nf` [zen_stone] DSL2 - revision: 37ff61f926
executor > local (3)
executor > local (3)
[fd/2642e9] process > PROCESS_FILES (2) [ 66%] 2 of 3, failed: 2
ERROR ~ Error executing process > 'PROCESS_FILES (3)'
Caused by:
Missing output file(s) `sample3.txt` expected by process `PROCESS_FILES (3)`
Command executed:
echo "Processing sample3" > sample3_output.txt
Command exit status:
0
Command output:
(empty)
Work dir:
/workspaces/training/side-quests/debugging/work/02/9604d49fb8200a74d737c72a6c98ed
Tip: when you have fixed the problem you can continue the execution adding the option `-resume` to the run command line
-- Check '.nextflow.log' file for details
Esaminate il codice¶
Il messaggio di errore indica che il processo si aspettava di produrre un file di output chiamato sample3.txt, ma lo script crea effettivamente sample3_output.txt. Esaminiamo la definizione del processo in missing_output.nf:
| missing_output.nf | |
|---|---|
Dovreste vedere che c'è una mancata corrispondenza tra il nome del file di output nel blocco output: e quello usato nello script. Questa mancata corrispondenza causa il fallimento del processo. Se incontrate questo tipo di errore, tornate indietro e verificate che gli output corrispondano tra la definizione del processo e il blocco output.
Se il problema non è ancora chiaro, controllate la directory di lavoro stessa per identificare i file di output effettivamente creati:
Per questo esempio questo ci evidenzierebbe che un suffisso _output viene incorporato nel nome del file di output, contrariamente alla nostra definizione output:.
Correggete il codice¶
Correggete la mancata corrispondenza rendendo il nome del file di output coerente:
Eseguite la pipeline¶
Output del comando
3.2. Software mancante¶
Un'altra classe di errori si verifica a causa di errori nel provisioning del software. missing_software.nf è un workflow sintatticamente valido, ma dipende da un software esterno per fornire il comando cowpy che utilizza.
Eseguite la pipeline¶
Output del comando
ERROR ~ Error executing process > 'PROCESS_FILES (3)'
Caused by:
Process `PROCESS_FILES (3)` terminated with an error exit status (127)
Command executed:
cowpy sample3 > sample3_output.txt
Command exit status:
127
Command output:
(empty)
Command error:
.command.sh: line 2: cowpy: command not found
Work dir:
/workspaces/training/side-quests/debugging/work/82/42a5bfb60c9c6ee63ebdbc2d51aa6e
Tip: you can try to figure out what's wrong by changing to the process work directory and showing the script file named `.command.sh`
-- Check '.nextflow.log' file for details
Il processo non ha accesso al comando che stiamo specificando. A volte questo accade perché uno script è presente nella directory bin del workflow, ma non è stato reso eseguibile. Altre volte è perché il software non è installato nel container o nell'ambiente in cui il workflow è in esecuzione.
Esaminate il codice¶
Fate attenzione a quel codice di uscita 127 - vi dice esattamente il problema. Esaminiamo missing_software.nf:
| missing_software.nf | |
|---|---|
Correggete il codice¶
Siamo stati un po' disonesti qui, e in realtà non c'è nulla di sbagliato nel codice. Dobbiamo solo specificare la configurazione necessaria per eseguire il processo in modo tale che abbia accesso al comando in questione. In questo caso il processo ha una definizione di container, quindi tutto ciò che dobbiamo fare è eseguire il workflow con Docker abilitato.
Eseguite la pipeline¶
Abbiamo impostato un profilo Docker per voi in nextflow.config, quindi potete eseguire il workflow con:
Output del comando
Nota
Per saperne di più su come Nextflow usa i container, vedere Hello Nextflow
3.3. Configurazione delle risorse errata¶
Nell'uso in produzione, configurerete le risorse sui vostri processi. Ad esempio memory definisce la quantità massima di memoria disponibile per il vostro processo, e se il processo la supera, il vostro scheduler tipicamente terminerà il processo e restituirà un codice di uscita 137. Non possiamo dimostrarlo qui perché stiamo usando l'executor local, ma possiamo mostrare qualcosa di simile con time.
Eseguite la pipeline¶
bad_resources.nf ha una configurazione del processo con un limite di tempo irrealistico di 1 millisecondo:
Output del comando
N E X T F L O W ~ version 25.10.2
Launching `bad_resources.nf` [disturbed_elion] DSL2 - revision: 27d2066e86
executor > local (3)
[c0/ded8e1] PROCESS_FILES (3) | 0 of 3 ✘
ERROR ~ Error executing process > 'PROCESS_FILES (2)'
Caused by:
Process exceeded running time limit (1ms)
Command executed:
cowpy sample2 > sample2_output.txt
Command exit status:
-
Command output:
(empty)
Work dir:
/workspaces/training/side-quests/debugging/work/53/f0a4cc56d6b3dc2a6754ff326f1349
Container:
community.wave.seqera.io/library/cowpy:1.1.5--3db457ae1977a273
Tip: you can replicate the issue by changing to the process work dir and entering the command `bash .command.run`
-- Check '.nextflow.log' file for details
Esaminate il codice¶
Esaminiamo bad_resources.nf:
| bad_resources.nf | |
|---|---|
Sappiamo che il processo richiederà più di un secondo (abbiamo aggiunto un sleep per assicurarcelo), ma il processo è impostato per scadere dopo 1 millisecondo. Qualcuno è stato un po' irrealistico con la sua configurazione!
Correggete il codice¶
Aumentate il limite di tempo a un valore realistico:
| bad_resources.nf | |
|---|---|
Eseguite la pipeline¶
Output del comando
Se vi assicurate di leggere i vostri messaggi di errore, fallimenti come questo non dovrebbero confondervi a lungo. Ma assicuratevi di capire i requisiti di risorse dei comandi che state eseguendo in modo da poter configurare le vostre direttive di risorse in modo appropriato.
3.4. Tecniche di debug dei processi¶
Quando i processi falliscono o si comportano in modo inatteso, avete bisogno di tecniche sistematiche per investigare cosa è andato storto. La directory di lavoro contiene tutte le informazioni necessarie per fare il debug dell'esecuzione del processo.
Utilizzo dell'ispezione della directory di lavoro¶
Lo strumento di debug più potente per i processi è l'esame della directory di lavoro. Quando un processo fallisce, Nextflow crea una directory di lavoro per quella specifica esecuzione del processo contenente tutti i file necessari per capire cosa è successo.
Eseguite la pipeline¶
Usiamo l'esempio missing_output.nf di prima per dimostrare l'ispezione della directory di lavoro (rigenerate una mancata corrispondenza nel nome del file di output se necessario):
Output del comando
N E X T F L O W ~ version 25.10.2
Launching `missing_output.nf` [irreverent_payne] DSL2 - revision: 3d5117f7e2
executor > local (3)
[5d/d544a4] PROCESS_FILES (2) | 0 of 3 ✘
ERROR ~ Error executing process > 'PROCESS_FILES (1)'
Caused by:
Missing output file(s) `sample1.txt` expected by process `PROCESS_FILES (1)`
Command executed:
echo "Processing sample1" > sample1_output.txt
Command exit status:
0
Command output:
(empty)
Work dir:
/workspaces/training/side-quests/debugging/work/1e/2011154d0b0f001cd383d7364b5244
Tip: you can replicate the issue by changing to the process work dir and entering the command `bash .command.run`
-- Check '.nextflow.log' file for details
Esaminate la directory di lavoro¶
Quando ricevete questo errore, la directory di lavoro contiene tutte le informazioni di debug. Trovate il percorso della directory di lavoro dal messaggio di errore ed esaminate il suo contenuto:
Potete quindi esaminare i file chiave:
Controllate lo script del comando¶
Il file .command.sh mostra esattamente quale comando è stato eseguito:
Questo rivela:
- Sostituzione delle variabili: Se le variabili Nextflow sono state correttamente espanse
- Percorsi dei file: Se i file di input erano correttamente localizzati
- Struttura del comando: Se la sintassi dello script è corretta
Problemi comuni da cercare:
- Virgolette mancanti: Le variabili contenenti spazi necessitano di virgolette appropriate
- Percorsi dei file errati: File di input che non esistono o si trovano in posizioni errate
- Nomi di variabili errati: Errori di battitura nei riferimenti alle variabili
- Configurazione dell'ambiente mancante: Comandi che dipendono da ambienti specifici
Controllate l'output degli errori¶
Il file .command.err contiene i messaggi di errore effettivi:
Questo file mostrerà:
- Codici di uscita: 127 (comando non trovato), 137 (terminato), ecc.
- Errori di permesso: Problemi di accesso ai file
- Errori del software: Messaggi di errore specifici dell'applicazione
- Errori di risorse: Memoria/limite di tempo superato
Controllate l'output standard¶
Il file .command.out mostra cosa ha prodotto il vostro comando:
Questo aiuta a verificare:
- Output atteso: Se il comando ha prodotto i risultati corretti
- Esecuzione parziale: Se il comando è iniziato ma è fallito a metà
- Informazioni di debug: Qualsiasi output diagnostico dal vostro script
Controllate il codice di uscita¶
Il file .exitcode contiene il codice di uscita per il processo:
Codici di uscita comuni e i loro significati:
- Codice di uscita 127: Comando non trovato - verificate l'installazione del software
- Codice di uscita 137: Processo terminato - verificate i limiti di memoria/tempo
Controllate l'esistenza dei file¶
Quando i processi falliscono a causa di file di output mancanti, verificate quali file sono stati effettivamente creati:
Questo aiuta a identificare:
- Mancate corrispondenze nei nomi dei file: File di output con nomi diversi da quelli attesi
- Problemi di permesso: File che non potevano essere creati
- Problemi di percorso: File creati in directory errate
Nel nostro esempio precedente, questo ci ha confermato che mentre il nostro sample3.txt atteso non era presente, sample3_output.txt era presente:
Takeaway¶
Il debug dei processi richiede l'esame delle directory di lavoro per capire cosa è andato storto. I file chiave includono .command.sh (lo script eseguito), .command.err (messaggi di errore) e .command.out (output standard). I codici di uscita come 127 (comando non trovato) e 137 (processo terminato) forniscono indizi diagnostici immediati sul tipo di fallimento.
Cosa c'è dopo?¶
Imparate gli strumenti di debug integrati di Nextflow e gli approcci sistematici alla risoluzione dei problemi.
4. Strumenti di Debug Integrati e Tecniche Avanzate¶
Nextflow fornisce diversi potenti strumenti integrati per il debug e l'analisi dell'esecuzione del workflow. Questi strumenti vi aiutano a capire cosa è andato storto, dove è andato storto e come correggerlo in modo efficiente.
4.1. Output del processo in tempo reale¶
A volte è necessario vedere cosa sta succedendo all'interno dei processi in esecuzione. Potete abilitare l'output del processo in tempo reale, che vi mostra esattamente cosa sta facendo ogni attività mentre viene eseguita.
Eseguite la pipeline¶
bad_channel_shape_viewed.nf dei nostri esempi precedenti stampava il contenuto del canale usando .view(), ma possiamo anche usare la direttiva debug per fare l'echo delle variabili dall'interno del processo stesso, come dimostriamo in bad_channel_shape_viewed_debug.nf. Eseguite il workflow:
Output del comando
N E X T F L O W ~ version 25.10.2
Launching `bad_channel_shape_viewed_debug.nf` [agitated_crick] DSL2 - revision: ea3676d9ec
executor > local (3)
[c6/2dac51] process > PROCESS_FILES (3) [100%] 3 of 3 ✔
Channel content: [sample1, file1.txt]
Channel content: [sample2, file2.txt]
Channel content: [sample3, file3.txt]
After mapping: sample1
After mapping: sample2
After mapping: sample3
Sample name inside process is sample2
Sample name inside process is sample1
Sample name inside process is sample3
Esaminate il codice¶
Esaminiamo bad_channel_shape_viewed_debug.nf per vedere come funziona la direttiva debug:
| bad_channel_shape_viewed_debug.nf | |
|---|---|
La direttiva debug può essere un modo rapido e conveniente per capire l'ambiente di un processo.
4.2. Modalità preview¶
A volte volete rilevare i problemi prima che vengano eseguiti i processi. Nextflow fornisce un flag per questo tipo di debug proattivo: -preview.
Eseguite la pipeline¶
La modalità preview vi permette di testare la logica del workflow senza eseguire i comandi. Questo può essere molto utile per verificare rapidamente la struttura del vostro workflow e assicurarsi che i processi siano connessi correttamente senza eseguire alcun comando effettivo.
Nota
Se avete corretto bad_syntax.nf in precedenza, reintroducete l'errore di sintassi rimuovendo la parentesi graffa di chiusura dopo il blocco script prima di eseguire questo comando.
Eseguite questo comando:
Output del comando
La modalità preview è particolarmente utile per rilevare gli errori di sintassi in anticipo senza eseguire alcun processo. Valida la struttura del workflow e le connessioni dei processi prima dell'esecuzione.
4.3. Stub running per il test della logica¶
A volte gli errori sono difficili da fare il debug perché i comandi richiedono troppo tempo, richiedono software speciale o falliscono per ragioni complesse. Lo stub running vi permette di testare la logica del workflow senza eseguire i comandi effettivi.
Eseguite la pipeline¶
Quando state sviluppando un processo Nextflow, potete usare la direttiva stub per definire comandi 'fittizi' che generano output della forma corretta senza eseguire il comando reale. Questo approccio è particolarmente prezioso quando volete verificare che la logica del vostro workflow sia corretta prima di affrontare le complessità del software effettivo.
Ad esempio, ricordate il nostro missing_software.nf di prima? Quello in cui avevamo software mancante che impediva l'esecuzione del workflow finché non aggiungessimo -profile docker? missing_software_with_stub.nf è un workflow molto simile. Se lo eseguiamo nello stesso modo, genereremo lo stesso errore:
Output del comando
ERROR ~ Error executing process > 'PROCESS_FILES (3)'
Caused by:
Process `PROCESS_FILES (3)` terminated with an error exit status (127)
Command executed:
cowpy sample3 > sample3_output.txt
Command exit status:
127
Command output:
(empty)
Command error:
.command.sh: line 2: cowpy: command not found
Work dir:
/workspaces/training/side-quests/debugging/work/82/42a5bfb60c9c6ee63ebdbc2d51aa6e
Tip: you can try to figure out what's wrong by changing to the process work directory and showing the script file named `.command.sh`
-- Check '.nextflow.log' file for details
Tuttavia, questo workflow non produrrà errori se lo eseguiamo con -stub-run, anche senza il profilo docker:
Output del comando
Esaminate il codice¶
Esaminiamo missing_software_with_stub.nf:
| missing_software.nf (with stub) | |
|---|---|
Rispetto a missing_software.nf, questo processo ha una direttiva stub: che specifica un comando da usare al posto di quello specificato in script:, nel caso in cui Nextflow venga eseguito in modalità stub.
Il comando touch che stiamo usando qui non dipende da alcun software o input appropriati, e verrà eseguito in tutte le situazioni, permettendoci di fare il debug della logica del workflow senza preoccuparci degli aspetti interni del processo.
Lo stub running aiuta a fare il debug di:
- Struttura dei canali e flusso di dati
- Connessioni e dipendenze dei processi
- Propagazione dei parametri
- Logica del workflow senza dipendenze software
4.4. Approccio sistematico al debug¶
Ora che avete imparato le singole tecniche di debug - dai file di trace e dalle directory di lavoro alla modalità preview, allo stub running e al monitoraggio delle risorse - colleghiamole insieme in una metodologia sistematica. Avere un approccio strutturato vi impedisce di essere sopraffatti da errori complessi e assicura che non perdiate indizi importanti.
Questa metodologia combina tutti gli strumenti che abbiamo trattato in un flusso di lavoro efficiente:
Metodo di debug in quattro fasi:
Fase 1: Risoluzione degli errori di sintassi (5 minuti)
- Verificate la presenza di sottolineature rosse in VSCode o nel vostro IDE
- Eseguite
nextflow run workflow.nf -previewper identificare i problemi di sintassi - Correggete tutti gli errori di sintassi (parentesi graffe mancanti, virgole finali, ecc.)
- Assicuratevi che il workflow venga analizzato correttamente prima di procedere
Fase 2: Valutazione rapida (5 minuti)
- Leggete attentamente i messaggi di errore a runtime
- Verificate se si tratta di un errore di runtime, logica o risorse
- Usate la modalità preview per testare la logica di base del workflow
Fase 3: Indagine dettagliata (15-30 minuti)
- Trovate la directory di lavoro dell'attività fallita
- Esaminate i file di log
- Aggiungete operatori
.view()per ispezionare i canali - Usate
-stub-runper testare la logica del workflow senza esecuzione
Fase 4: Correzione e validazione (15 minuti)
- Apportate correzioni mirate e minimali
- Testate con resume:
nextflow run workflow.nf -resume - Verificate l'esecuzione completa del workflow
Utilizzo di resume per un debug efficiente
Una volta identificato un problema, avete bisogno di un modo efficiente per testare le vostre correzioni senza sprecare tempo a rieseguire le parti riuscite del vostro workflow. La funzionalità -resume di Nextflow è preziosa per il debug.
Avrete incontrato -resume se avete lavorato attraverso Hello Nextflow, ed è importante che ne facciate buon uso durante il debug per risparmiarvi l'attesa mentre i processi prima del vostro processo problematico vengono eseguiti.
Strategia di debug con resume:
- Eseguite il workflow fino al fallimento
- Esaminate la directory di lavoro per l'attività fallita
- Correggete il problema specifico
- Riprendete per testare solo la correzione
- Ripetete fino al completamento del workflow
Profilo di configurazione per il debug¶
Per rendere questo approccio sistematico ancora più efficiente, potete creare una configurazione di debug dedicata che abilita automaticamente tutti gli strumenti di cui avete bisogno:
| nextflow.config (debug profile) | |
|---|---|
Potete quindi eseguire la pipeline con questo profilo abilitato:
Questo profilo abilita l'output in tempo reale, preserva le directory di lavoro e limita la parallelizzazione per un debug più semplice.
4.5. Esercizio pratico di debug¶
Ora è il momento di mettere in pratica l'approccio sistematico al debug. Il workflow buggy_workflow.nf contiene diversi errori comuni che rappresentano i tipi di problemi che incontrerete nello sviluppo reale.
Esercizio
Usate l'approccio sistematico al debug per identificare e correggere tutti gli errori in buggy_workflow.nf. Questo workflow tenta di elaborare dati di campioni da un file CSV ma contiene molteplici bug intenzionali che rappresentano scenari di debug comuni.
Iniziate eseguendo il workflow per vedere il primo errore:
Output del comando
N E X T F L O W ~ version 25.10.2
Launching `buggy_workflow.nf` [wise_ramanujan] DSL2 - revision: d51a8e83fd
ERROR ~ Range [11, 12) out of bounds for length 11
-- Check '.nextflow.log' file for details
Questo errore criptico indica un problema di analisi intorno alle righe 11-12 nel blocco params{}. Il parser v2 rileva i problemi strutturali in anticipo.
Applicate il metodo di debug in quattro fasi che avete imparato:
Fase 1: Risoluzione degli errori di sintassi
- Verificate la presenza di sottolineature rosse in VSCode o nel vostro IDE
- Eseguite nextflow run workflow.nf -preview per identificare i problemi di sintassi
- Correggete tutti gli errori di sintassi (parentesi graffe mancanti, virgole finali, ecc.)
- Assicuratevi che il workflow venga analizzato correttamente prima di procedere
Fase 2: Valutazione rapida
- Leggete attentamente i messaggi di errore a runtime
- Identificate se gli errori sono di runtime, logica o risorse
- Usate la modalità -preview per testare la logica di base del workflow
Fase 3: Indagine dettagliata
- Esaminate le directory di lavoro per le attività fallite
- Aggiungete operatori .view() per ispezionare i canali
- Controllate i file di log nelle directory di lavoro
- Usate -stub-run per testare la logica del workflow senza esecuzione
Fase 4: Correzione e validazione
- Apportate correzioni mirate
- Usate -resume per testare le correzioni in modo efficiente
- Verificate l'esecuzione completa del workflow
Strumenti di debug a vostra disposizione:
# Modalità preview per il controllo della sintassi
nextflow run buggy_workflow.nf -preview
# Profilo debug per output dettagliato
nextflow run buggy_workflow.nf -profile debug
# Stub running per il test della logica
nextflow run buggy_workflow.nf -stub-run
# Resume dopo le correzioni
nextflow run buggy_workflow.nf -resume
Soluzione
Il buggy_workflow.nf contiene 9 o 10 errori distinti (a seconda di come li si conta) che coprono tutte le principali categorie di debug. Ecco una suddivisione sistematica di ogni errore e come correggerlo
Iniziamo con quegli errori di sintassi:
Errore 1: Errore di sintassi - Virgola finale
Correzione: Rimuovete la virgola finaleErrore 2: Errore di sintassi - Parentesi graffa di chiusura mancante
Errore 3: Errore nel nome della variabile
Errore 4: Errore di variabile non definita
A questo punto il workflow verrà eseguito, ma riceveremo ancora errori (ad es. Path value cannot be null in processFiles), causati da una struttura del canale errata.
Errore 5: Errore di struttura del canale - Output map errato
Ma questo romperà la nostra correzione per l'esecuzione di heavyProcess() sopra, quindi dovremo usare un map per passare solo gli ID dei campioni a quel processo:
Errore 6: Struttura del canale errata per heavyProcess
Ora andiamo un po' più avanti ma riceviamo un errore su No such variable: i, perché non abbiamo fatto l'escape di una variabile Bash.
Errore 7: Errore di escape della variabile Bash
Ora otteniamo Process exceeded running time limit (1ms), quindi correggiamo il limite di tempo di esecuzione per il processo rilevante:
Errore 8: Errore di configurazione delle risorse
Successivamente abbiamo un errore Missing output file(s) da risolvere:
Errore 9: Mancata corrispondenza nel nome del file di output
I primi due processi sono stati eseguiti, ma non il terzo.
Errore 10: Mancata corrispondenza nel nome del file di output
Con questo, l'intero workflow dovrebbe essere eseguito.
Workflow corretto completo:
Categorie di errori trattate:
- Errori di sintassi: Parentesi graffe mancanti, virgole finali, variabili non definite
- Errori di struttura dei canali: Forme dei dati errate, canali non definiti
- Errori di processo: Mancate corrispondenze nei file di output, escape delle variabili
- Errori di risorse: Limiti di tempo irrealistici
Lezioni chiave di debug:
- Leggete attentamente i messaggi di errore - spesso puntano direttamente al problema
- Usate approcci sistematici - correggete un errore alla volta e testate con
-resume - Capite il flusso di dati - gli errori di struttura dei canali sono spesso i più sottili
- Controllate le directory di lavoro - quando i processi falliscono, i log vi dicono esattamente cosa è andato storto
Riepilogo¶
In questa side quest, avete imparato un insieme di tecniche sistematiche per il debug dei workflow Nextflow. Applicare queste tecniche nel vostro lavoro vi permetterà di trascorrere meno tempo a combattere con il computer, risolvere i problemi più velocemente e proteggervi da problemi futuri.
Pattern chiave¶
1. Come identificare e correggere gli errori di sintassi:
- Interpretare i messaggi di errore di Nextflow e localizzare i problemi
- Errori di sintassi comuni: parentesi graffe mancanti, parole chiave errate, variabili non definite
- Distinguere tra variabili Nextflow (Groovy) e Bash
- Utilizzo delle funzionalità dell'estensione VS Code per il rilevamento precoce degli errori
// Parentesi graffa mancante - cercate le sottolineature rosse nell'IDE
process FOO {
script:
"""
echo "hello"
"""
// } <-- mancante!
// Parola chiave errata
inputs: // Dovrebbe essere 'input:'
// Variabile non definita - fate l'escape con backslash per le variabili Bash
echo "${undefined_var}" // Variabile Nextflow (errore se non definita)
echo "\${bash_var}" // Variabile Bash (con escape)
2. Come fare il debug dei problemi di struttura dei canali:
- Comprendere la cardinalità dei canali e i problemi di esaurimento
- Fare il debug delle mancate corrispondenze nella struttura del contenuto dei canali
- Utilizzo degli operatori
.view()per l'ispezione dei canali - Riconoscere i pattern di errore come le parentesi quadre nell'output
// Ispeziona il contenuto del canale
my_channel.view { "Content: $it" }
// Converti il canale di coda in value channel (previene l'esaurimento)
reference_ch = channel.value('ref.fa')
// oppure
reference_ch = channel.of('ref.fa').first()
3. Come risolvere i problemi di esecuzione dei processi:
- Diagnosticare gli errori di file di output mancanti
- Comprendere i codici di uscita (127 per software mancante, 137 per problemi di memoria)
- Investigare le directory di lavoro e i file dei comandi
- Configurare le risorse in modo appropriato
# Controlla cosa è stato effettivamente eseguito
cat work/ab/cdef12/.command.sh
# Controlla l'output degli errori
cat work/ab/cdef12/.command.err
# Codice di uscita 127 = comando non trovato
# Codice di uscita 137 = terminato (limite di memoria/tempo)
4. Come usare gli strumenti di debug integrati di Nextflow:
- Sfruttare la modalità preview e il debug in tempo reale
- Implementare lo stub running per il test della logica
- Applicare resume per cicli di debug efficienti
- Seguire una metodologia di debug sistematica in quattro fasi
Riferimento rapido per il debug
Errori di sintassi? → Controllate gli avvisi di VSCode, eseguite nextflow run workflow.nf -preview
Problemi con i canali? → Usate .view() per ispezionare il contenuto: my_channel.view()
Fallimenti dei processi? → Controllate i file della directory di lavoro:
.command.sh- lo script eseguito.command.err- messaggi di errore.exitcode- stato di uscita (127 = comando non trovato, 137 = terminato)
Comportamento misterioso? → Eseguite con -stub-run per testare la logica del workflow
Avete apportato correzioni? → Usate -resume per risparmiare tempo nei test: nextflow run workflow.nf -resume
Risorse aggiuntive¶
- Guida alla risoluzione dei problemi di Nextflow: Documentazione ufficiale per la risoluzione dei problemi
- Comprensione dei canali Nextflow: Approfondimento sui tipi di canali e il loro comportamento
- Riferimento alle direttive di processo: Tutte le opzioni di configurazione dei processi disponibili
- nf-test: Framework di test per le pipeline Nextflow
- Community Slack di Nextflow: Ottenete aiuto dalla community
Per i workflow in produzione, considerate:
- La configurazione di Seqera Platform per il monitoraggio e il debug su larga scala
- L'utilizzo di Wave containers per ambienti software riproducibili
Ricordate: Il debug efficace è una competenza che migliora con la pratica. La metodologia sistematica e il toolkit completo che avete acquisito qui vi serviranno bene durante tutto il vostro percorso di sviluppo Nextflow.
Cosa c'è dopo?¶
Tornate al menu delle Side Quests o cliccate il pulsante in basso a destra della pagina per passare all'argomento successivo nell'elenco.