Debugowanie Workflow'ów¶
Tłumaczenie wspomagane przez AI - dowiedz się więcej i zasugeruj ulepszenia
Debugowanie to kluczowa umiejętność, która może zaoszczędzić Ci wiele godzin frustracji i pomóc stać się bardziej efektywnym programistą Nextflow. W trakcie swojej kariery, szczególnie na początku, będziesz napotykać błędy podczas budowania i utrzymywania workflow'ów. Nauka systematycznych podejść do debugowania pomoże Ci szybko identyfikować i rozwiązywać problemy.
Cele szkolenia¶
W tym side queście poznamy systematyczne techniki debugowania workflow'ów Nextflow:
- Debugowanie błędów składni: Efektywne korzystanie z funkcji IDE i komunikatów o błędach Nextflow
- Debugowanie kanałów: Diagnozowanie problemów z przepływem danych i strukturą kanałów
- Debugowanie procesów: Badanie błędów wykonania i problemów z zasobami
- Wbudowane narzędzia debugowania: Korzystanie z trybu podglądu Nextflow, stub running i katalogów roboczych
- Systematyczne podejścia: Czterofazowa metodologia efektywnego debugowania
Po zakończeniu będziesz dysponować solidną metodologią debugowania, która przekształca frustrujące komunikaty o błędach w czytelne wskazówki prowadzące do rozwiązań.
Wymagania wstępne¶
Przed podjęciem tego side questu powinieneś/powinnaś:
- Ukończyć samouczek Hello Nextflow lub równoważny kurs dla początkujących.
- Swobodnie posługiwać się podstawowymi konceptami i mechanizmami Nextflow (procesy, kanały, operatory)
Opcjonalnie: Zalecamy wcześniejsze ukończenie side questu IDE Features for Nextflow Development. Obejmuje on kompleksowe omówienie funkcji IDE wspierających debugowanie (podświetlanie składni, wykrywanie błędów itp.), z których będziemy tu intensywnie korzystać.
0. Pierwsze kroki¶
Otwórz środowisko szkoleniowe¶
Jeśli jeszcze tego nie zrobiłeś/zrobiłaś, otwórz środowisko szkoleniowe zgodnie z opisem w sekcji Konfiguracja środowiska.
![]()
Przejdź do katalogu projektu¶
Przejdźmy do katalogu, w którym znajdują się pliki tego samouczka.
Możesz ustawić VSCode tak, aby skupiał się na tym katalogu:
Przejrzyj materiały¶
Znajdziesz tu zestaw przykładowych workflow'ów z różnymi rodzajami błędów, których użyjemy do ćwiczeń:
Zawartość katalogu
.
├── bad_bash_var.nf
├── bad_channel_shape.nf
├── bad_channel_shape_viewed_debug.nf
├── bad_channel_shape_viewed.nf
├── bad_number_inputs.nf
├── badpractice_syntax.nf
├── bad_resources.nf
├── bad_syntax.nf
├── buggy_workflow.nf
├── data
│ ├── sample_001.fastq.gz
│ ├── sample_002.fastq.gz
│ ├── sample_003.fastq.gz
│ ├── sample_004.fastq.gz
│ ├── sample_005.fastq.gz
│ └── sample_data.csv
├── exhausted.nf
├── invalid_process.nf
├── missing_output.nf
├── missing_software.nf
├── missing_software_with_stub.nf
├── nextflow.config
└── no_such_var.nf
Pliki te reprezentują typowe scenariusze debugowania, z którymi spotkasz się w rzeczywistym środowisku programistycznym.
Zapoznaj się z zadaniem¶
Twoim wyzwaniem jest uruchomienie każdego workflow'u, zidentyfikowanie błędów i ich naprawienie.
Dla każdego błędnego workflow'u:
- Uruchom workflow i zaobserwuj błąd
- Przeanalizuj komunikat o błędzie: co mówi Ci Nextflow?
- Zlokalizuj problem w kodzie, korzystając z dostarczonych wskazówek
- Napraw błąd i zweryfikuj, że rozwiązanie działa
- Zresetuj plik przed przejściem do następnej sekcji (użyj
git checkout <filename>)
Ćwiczenia przechodzą od prostych błędów składni do bardziej subtelnych problemów w czasie wykonania. Rozwiązania są omawiane na bieżąco, ale spróbuj rozwiązać każde z nich samodzielnie przed przeczytaniem dalej.
Lista kontrolna gotowości¶
Myślisz, że jesteś gotowy/gotowa?
- Rozumiem cel tego kursu i jego wymagania wstępne
- Moje środowisko jest uruchomione i działa
- Ustawiłem/ustawiłam odpowiedni katalog roboczy
- Rozumiem zadanie
Jeśli możesz zaznaczyć wszystkie pola, możesz zaczynać.
1. Błędy składni¶
Błędy składni to najczęstszy rodzaj błędów, z jakimi spotkasz się podczas pisania kodu Nextflow. Występują, gdy kod nie jest zgodny z oczekiwanymi regułami składni DSL Nextflow. Uniemożliwiają one uruchomienie workflow'u, dlatego ważne jest, aby nauczyć się je szybko identyfikować i naprawiać.
1.1. Brakujące nawiasy klamrowe¶
Jednym z najczęstszych błędów składni, a zarazem jednym z trudniejszych do debugowania, są brakujące lub niedopasowane nawiasy klamrowe.
Zacznijmy od praktycznego przykładu.
Uruchom pipeline¶
Wyjście polecenia
Kluczowe elementy komunikatów o błędach składni:
- Plik i lokalizacja: Wskazuje, który plik i wiersz/kolumna zawierają błąd (
bad_syntax.nf:24:1) - Opis błędu: Wyjaśnia, co parser napotkał, czego się nie spodziewał (
Unexpected input: '<EOF>') - Wskaźnik EOF: Komunikat
<EOF>(End Of File) oznacza, że parser dotarł do końca pliku, wciąż oczekując dalszej zawartości — klasyczny znak niezamkniętych nawiasów klamrowych
Sprawdź kod¶
Przyjrzyjmy się teraz bad_syntax.nf, aby zrozumieć przyczynę błędu:
Na potrzeby tego przykładu zostawiliśmy komentarz wskazujący miejsce błędu. Rozszerzenie Nextflow dla VSCode powinno również dawać Ci wskazówki dotyczące problemu — zaznacza niedopasowany nawias na czerwono i podświetla przedwczesny koniec pliku:
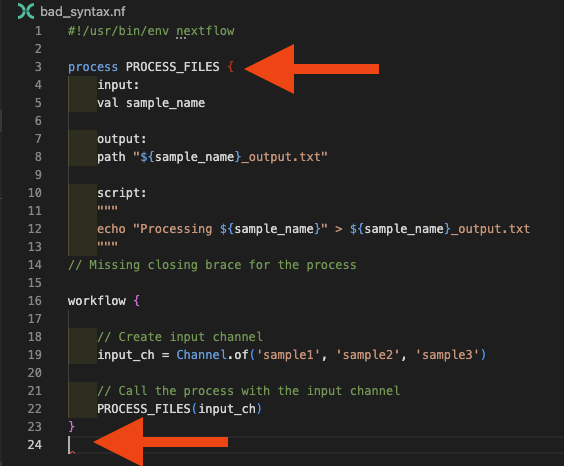
Strategia debugowania błędów nawiasów:
- Użyj dopasowywania nawiasów w VS Code (umieść kursor obok nawiasu)
- Sprawdź panel Problems pod kątem komunikatów związanych z nawiasami
- Upewnij się, że każdy otwierający
{ma odpowiadający mu zamykający}
Napraw kod¶
Zastąp komentarz brakującym nawiasem zamykającym:
Uruchom pipeline¶
Uruchom workflow ponownie, aby potwierdzić, że działa:
Wyjście polecenia
1.2. Używanie nieprawidłowych słów kluczowych lub dyrektyw procesu¶
Innym częstym błędem składni jest nieprawidłowa definicja procesu. Może się to zdarzyć, gdy zapomnisz zdefiniować wymagane bloki lub użyjesz nieprawidłowych dyrektyw w definicji procesu.
Uruchom pipeline¶
Wyjście polecenia
N E X T F L O W ~ version 25.10.2
Launching `invalid_process.nf` [nasty_jepsen] DSL2 - revision: da9758d614
Error invalid_process.nf:3:1: Invalid process definition -- check for missing or out-of-order section labels
│ 3 | process PROCESS_FILES {
│ | ^^^^^^^^^^^^^^^^^^^^^^^
│ 4 | inputs:
│ 5 | val sample_name
│ 6 |
╰ 7 | output:
ERROR ~ Script compilation failed
-- Check '.nextflow.log' file for details
Sprawdź kod¶
Komunikat o błędzie wskazuje na „Invalid process definition" i pokazuje kontekst wokół problemu. Patrząc na wiersze 3–7, widzimy inputs: w wierszu 4 — to właśnie jest problem. Przyjrzyjmy się invalid_process.nf:
Patrząc na wiersz 4 w kontekście błędu, możemy dostrzec problem: używamy inputs zamiast poprawnej dyrektywy input. Rozszerzenie Nextflow dla VSCode również to oznaczy:
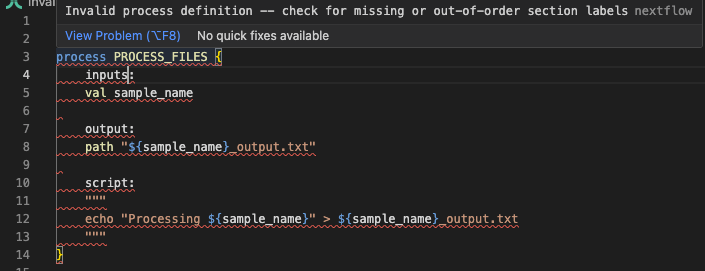
Napraw kod¶
Zastąp nieprawidłowe słowo kluczowe poprawnym, korzystając z dokumentacji:
Uruchom pipeline¶
Uruchom workflow ponownie, aby potwierdzić, że działa:
Wyjście polecenia
1.3. Używanie nieprawidłowych nazw zmiennych¶
Nazwy zmiennych używane w blokach skryptu muszą być prawidłowe — muszą pochodzić z wejść lub z kodu Groovy wstawionego przed skryptem. Jednak gdy na początku tworzenia pipeline'u zmagasz się ze złożonością, łatwo popełnić błędy w nazewnictwie zmiennych, a Nextflow szybko Cię o tym poinformuje.
Uruchom pipeline¶
Wyjście polecenia
N E X T F L O W ~ version 25.10.2
Launching `no_such_var.nf` [gloomy_meninsky] DSL2 - revision: 0c4d3bc28c
Error no_such_var.nf:17:39: `undefined_var` is not defined
│ 17 | echo "Using undefined variable: ${undefined_var}" >> ${output_pref
╰ | ^^^^^^^^^^^^^
ERROR ~ Script compilation failed
-- Check '.nextflow.log' file for details
Błąd jest wykrywany w czasie kompilacji i wskazuje bezpośrednio na niezdefiniowaną zmienną w wierszu 17, a daszek precyzyjnie pokazuje miejsce problemu.
Sprawdź kod¶
Przyjrzyjmy się no_such_var.nf:
Komunikat o błędzie wskazuje, że zmienna nie jest rozpoznawana w szablonie skryptu — i rzeczywiście, możesz zobaczyć ${undefined_var} użyte w bloku skryptu, ale niezdefiniowane nigdzie indziej.
Napraw kod¶
Jeśli otrzymasz błąd „No such variable", możesz go naprawić, definiując zmienną (poprawiając nazwy zmiennych wejściowych lub edytując kod Groovy przed skryptem) albo usuwając ją z bloku skryptu, jeśli nie jest potrzebna:
Uruchom pipeline¶
Uruchom workflow ponownie, aby potwierdzić, że działa:
Wyjście polecenia
1.4. Nieprawidłowe użycie zmiennych Bash¶
Na początku pracy z Nextflow trudno jest zrozumieć różnicę między zmiennymi Nextflow (Groovy) a zmiennymi Bash. Może to generować inną postać błędu złej zmiennej, który pojawia się przy próbie użycia zmiennych w zawartości Bash bloku skryptu.
Uruchom pipeline¶
Wyjście polecenia
N E X T F L O W ~ version 25.10.2
Launching `bad_bash_var.nf` [infallible_mandelbrot] DSL2 - revision: 0853c11080
Error bad_bash_var.nf:13:42: `prefix` is not defined
│ 13 | echo "Processing ${sample_name}" > ${prefix}.txt
╰ | ^^^^^^
ERROR ~ Script compilation failed
-- Check '.nextflow.log' file for details
Sprawdź kod¶
Błąd wskazuje na wiersz 13, gdzie używane jest ${prefix}. Przyjrzyjmy się bad_bash_var.nf, aby zobaczyć przyczynę problemu:
| bad_bash_var.nf | |
|---|---|
W tym przykładzie definiujemy zmienną prefix w Bash, ale w procesie Nextflow składnia $, której użyliśmy do jej odwołania (${prefix}), jest interpretowana jako zmienna Groovy, a nie Bash. Zmienna nie istnieje w kontekście Groovy, więc otrzymujemy błąd „no such variable".
Napraw kod¶
Jeśli chcesz użyć zmiennej Bash, musisz poprzedzić znak dolara ukośnikiem odwrotnym:
| bad_bash_var.nf | |
|---|---|
To mówi Nextflow, aby interpretował tę zmienną jako zmienną Bash.
Uruchom pipeline¶
Uruchom workflow ponownie, aby potwierdzić, że działa:
Wyjście polecenia
Zmienne Groovy a zmienne Bash
W przypadku prostych operacji na zmiennych, takich jak konkatenacja ciągów znaków czy operacje na prefiksach/sufiksach, zazwyczaj bardziej czytelne jest używanie zmiennych Groovy w sekcji skryptu zamiast zmiennych Bash w bloku skryptu:
Takie podejście eliminuje potrzebę poprzedzania znaków dolara ukośnikiem i sprawia, że kod jest łatwiejszy do czytania i utrzymania.
1.5. Instrukcje poza blokiem workflow¶
Rozszerzenie Nextflow dla VSCode podświetla problemy ze strukturą kodu, które spowodują błędy. Typowym przykładem jest definiowanie kanałów poza blokiem workflow {} — jest to teraz egzekwowane jako błąd składni.
Uruchom pipeline¶
Wyjście polecenia
N E X T F L O W ~ version 25.10.2
Launching `badpractice_syntax.nf` [intergalactic_colden] DSL2 - revision: 5e4b291bde
Error badpractice_syntax.nf:3:1: Statements cannot be mixed with script declarations -- move statements into a process or workflow
│ 3 | input_ch = channel.of('sample1', 'sample2', 'sample3')
╰ | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR ~ Script compilation failed
-- Check '.nextflow.log' file for details
Komunikat o błędzie jasno wskazuje problem: instrukcje (takie jak definicje kanałów) nie mogą być mieszane z deklaracjami skryptu poza blokiem workflow lub process.
Sprawdź kod¶
Przyjrzyjmy się badpractice_syntax.nf, aby zobaczyć przyczynę błędu:
Rozszerzenie VSCode również podświetli zmienną input_ch jako zdefiniowaną poza blokiem workflow:
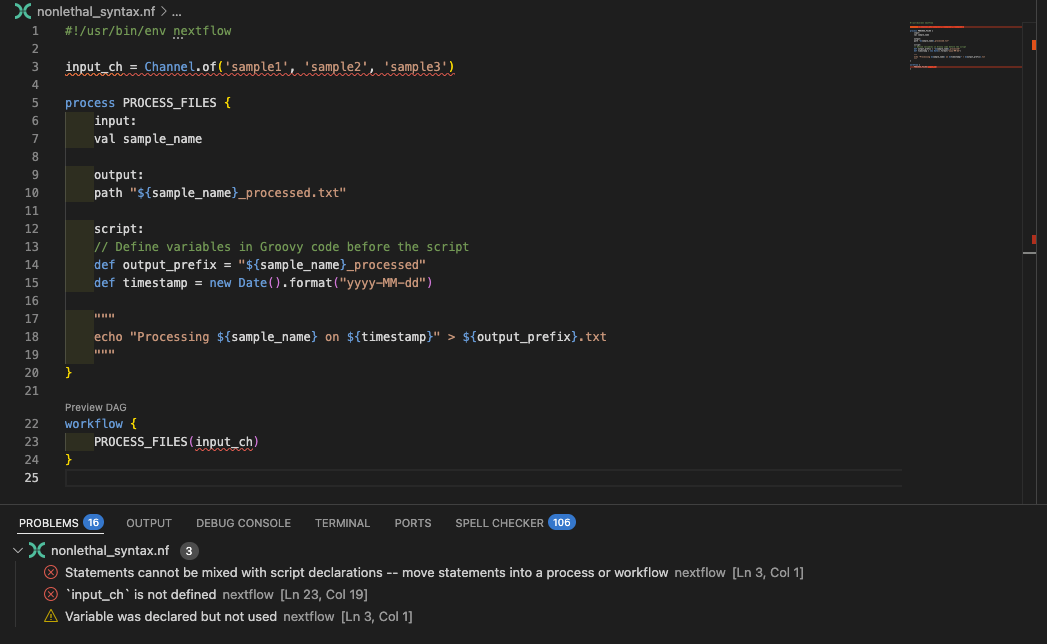
Napraw kod¶
Przenieś definicję kanału do bloku workflow:
Uruchom pipeline¶
Uruchom workflow ponownie, aby potwierdzić, że poprawka działa:
Wyjście polecenia
Definiuj kanały wejściowe wewnątrz bloku workflow i ogólnie stosuj się do innych zaleceń rozszerzenia.
Podsumowanie¶
Możesz systematycznie identyfikować i naprawiać błędy składni, korzystając z komunikatów o błędach Nextflow i wizualnych wskaźników IDE. Typowe błędy składni obejmują brakujące nawiasy klamrowe, nieprawidłowe słowa kluczowe procesów, niezdefiniowane zmienne oraz nieprawidłowe użycie zmiennych Bash kontra Nextflow. Rozszerzenie VSCode pomaga wykryć wiele z nich przed uruchomieniem. Mając te umiejętności debugowania składni w swoim arsenale, będziesz w stanie szybko rozwiązywać najczęstsze błędy składni Nextflow i przejść do bardziej złożonych problemów w czasie wykonania.
Co dalej?¶
Naucz się debugować bardziej złożone błędy struktury kanałów, które występują nawet gdy składnia jest poprawna.
2. Błędy struktury kanałów¶
Błędy struktury kanałów są bardziej subtelne niż błędy składni, ponieważ kod jest składniowo poprawny, ale kształty danych nie pasują do tego, czego oczekują procesy. Nextflow spróbuje uruchomić pipeline, ale może stwierdzić, że liczba wejść nie zgadza się z oczekiwaną i zakończyć działanie błędem. Tego rodzaju błędy zazwyczaj pojawiają się dopiero w czasie wykonania i wymagają zrozumienia danych przepływających przez workflow.
Debugowanie kanałów za pomocą .view()
W tej sekcji pamiętaj, że możesz używać operatora .view() do inspekcji zawartości kanału w dowolnym miejscu workflow'u. To jedno z najpotężniejszych narzędzi debugowania do rozumienia problemów ze strukturą kanałów. Szczegółowo omówimy tę technikę w sekcji 2.4, ale możesz jej używać już podczas pracy z przykładami.
2.1. Nieprawidłowa liczba kanałów wejściowych¶
Ten błąd występuje, gdy przekazujesz inną liczbę kanałów niż oczekuje proces.
Uruchom pipeline¶
Wyjście polecenia
N E X T F L O W ~ version 25.10.2
Launching `bad_number_inputs.nf` [happy_swartz] DSL2 - revision: d83e58dcd3
Error bad_number_inputs.nf:23:5: Incorrect number of call arguments, expected 1 but received 2
│ 23 | PROCESS_FILES(samples_ch, files_ch)
╰ | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ERROR ~ Script compilation failed
-- Check '.nextflow.log' file for details
Sprawdź kod¶
Komunikat o błędzie jasno stwierdza, że wywołanie oczekiwało 1 argumentu, ale otrzymało 2, i wskazuje na wiersz 23. Przyjrzyjmy się bad_number_inputs.nf:
Powinieneś/powinnaś zobaczyć niedopasowane wywołanie PROCESS_FILES, które dostarcza wiele kanałów wejściowych, podczas gdy proces definiuje tylko jeden. Rozszerzenie VSCode również podkreśli wywołanie procesu na czerwono i wyświetli komunikat diagnostyczny po najechaniu myszą:
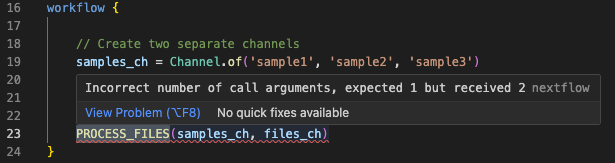
Napraw kod¶
W tym konkretnym przykładzie proces oczekuje jednego kanału i nie potrzebuje drugiego, więc możemy to naprawić, przekazując tylko kanał samples_ch:
Uruchom pipeline¶
Wyjście polecenia
Częściej niż w tym przykładzie możesz dodać dodatkowe wejścia do procesu i zapomnieć odpowiednio zaktualizować wywołanie workflow'u, co może prowadzić do tego rodzaju błędu. Na szczęście jest to jeden z łatwiejszych do zrozumienia i naprawienia błędów, ponieważ komunikat o błędzie jest dość jasny co do niezgodności.
2.2. Wyczerpanie kanału (proces uruchamia się rzadziej niż oczekiwano)¶
Niektóre błędy struktury kanałów są znacznie bardziej subtelne i nie generują żadnych błędów. Prawdopodobnie najczęstszy z nich odzwierciedla wyzwanie, z którym borykają się nowi użytkownicy Nextflow: zrozumienie, że kanały kolejki mogą się wyczerpać i skończyć im się elementy, co powoduje przedwczesne zakończenie workflow'u.
Uruchom pipeline¶
Wyjście polecenia
N E X T F L O W ~ version 25.10.2
Launching `exhausted.nf` [extravagant_gauss] DSL2 - revision: 08cff7ba2a
executor > local (1)
[bd/f61fff] PROCESS_FILES (1) [100%] 1 of 1 ✔
Workflow kończy się bez błędu, ale przetwarza tylko jedną próbkę!
Sprawdź kod¶
Przyjrzyjmy się exhausted.nf, aby sprawdzić, czy to prawidłowe zachowanie:
Proces uruchamia się tylko raz zamiast trzy razy, ponieważ reference_ch jest kanałem kolejki, który wyczerpuje się po pierwszym wykonaniu procesu. Gdy jeden kanał się wyczerpie, cały proces zatrzymuje się, nawet jeśli inne kanały wciąż mają elementy.
Jest to typowy wzorzec, gdy masz jeden plik referencyjny, który musi być wielokrotnie używany dla wielu próbek. Rozwiązaniem jest przekształcenie kanału referencyjnego w kanał wartości, który może być używany wielokrotnie.
Napraw kod¶
Istnieje kilka sposobów rozwiązania tego problemu, w zależności od liczby plików, których dotyczy.
Opcja 1: Masz jeden plik referencyjny, który wielokrotnie używasz. Możesz po prostu utworzyć kanał wartości, który można używać wielokrotnie. Są trzy sposoby, aby to zrobić:
1a Użyj channel.value():
| exhausted.nf (fixed - Option 1a) | |
|---|---|
1b Użyj operatora first() (dokumentacja):
| exhausted.nf (fixed - Option 1b) | |
|---|---|
1c. Użyj operatora collect() (dokumentacja):
| exhausted.nf (fixed - Option 1c) | |
|---|---|
Opcja 2: W bardziej złożonych scenariuszach, na przykład gdy masz wiele plików referencyjnych dla wszystkich próbek w kanale próbek, możesz użyć operatora combine, aby utworzyć nowy kanał łączący oba kanały w krotki:
| exhausted.nf (fixed - Option 2) | |
|---|---|
Operator .combine() generuje iloczyn kartezjański dwóch kanałów, więc każdy element reference_ch zostanie sparowany z każdym elementem input_ch. Pozwala to procesowi działać dla każdej próbki przy jednoczesnym korzystaniu z referencji.
Wymaga to dostosowania wejścia procesu. W naszym przykładzie początek definicji procesu należałoby zmienić następująco:
| exhausted.nf (fixed - Option 2) | |
|---|---|
Takie podejście może nie być odpowiednie we wszystkich sytuacjach.
Uruchom pipeline¶
Wypróbuj jedną z powyższych poprawek i uruchom workflow ponownie:
Wyjście polecenia
Teraz powinieneś/powinnaś zobaczyć, że wszystkie trzy próbki są przetwarzane, a nie tylko jedna.
2.3. Nieprawidłowa struktura zawartości kanału¶
Gdy workflow'y osiągają pewien poziom złożoności, trudno jest śledzić wewnętrzne struktury każdego kanału, a ludzie często generują niezgodności między tym, czego oczekuje proces, a tym, co faktycznie zawiera kanał. Jest to bardziej subtelne niż problem omówiony wcześniej, gdzie liczba kanałów była nieprawidłowa. W tym przypadku możesz mieć prawidłową liczbę kanałów wejściowych, ale wewnętrzna struktura jednego lub więcej z nich nie odpowiada temu, czego oczekuje proces.
Uruchom pipeline¶
Wyjście polecenia
Launching `bad_channel_shape.nf` [hopeful_pare] DSL2 - revision: ffd66071a1
executor > local (3)
executor > local (3)
[3f/c2dcb3] PROCESS_FILES (3) [ 0%] 0 of 3 ✘
ERROR ~ Error executing process > 'PROCESS_FILES (1)'
Caused by:
Missing output file(s) `[sample1, file1.txt]_output.txt` expected by process `PROCESS_FILES (1)`
Command executed:
echo "Processing [sample1, file1.txt]" > [sample1, file1.txt]_output.txt
Command exit status:
0
Command output:
(empty)
Work dir:
/workspaces/training/side-quests/debugging/work/d6/1fb69d1d93300bbc9d42f1875b981e
Tip: when you have fixed the problem you can continue the execution adding the option `-resume` to the run command line
-- Check '.nextflow.log' file for details
Sprawdź kod¶
Nawiasy kwadratowe w komunikacie o błędzie dają wskazówkę — proces traktuje krotkę jako pojedynczą wartość, co nie jest zamierzonym zachowaniem. Przyjrzyjmy się bad_channel_shape.nf:
Widać, że generujemy kanał złożony z krotek: ['sample1', 'file1.txt'], ale proces oczekuje pojedynczej wartości val sample_name. Wykonane polecenie pokazuje, że proces próbuje utworzyć plik o nazwie [sample3, file3.txt]_output.txt, co nie jest zamierzonym wyjściem.
Napraw kod¶
Aby to naprawić, jeśli proces wymaga obu wejść, możemy dostosować go do przyjmowania krotki:
| bad_channel_shape.nf | |
|---|---|
Uruchom pipeline¶
Wybierz jedno z rozwiązań i uruchom workflow ponownie:
Wyjście polecenia
2.4. Techniki debugowania kanałów¶
Używanie .view() do inspekcji kanałów¶
Najpotężniejszym narzędziem debugowania kanałów jest operator .view(). Pozwala on zrozumieć kształt kanałów na wszystkich etapach, co pomaga w debugowaniu.
Uruchom pipeline¶
Uruchom bad_channel_shape_viewed.nf, aby zobaczyć to w działaniu:
Wyjście polecenia
N E X T F L O W ~ version 25.10.2
Launching `bad_channel_shape_viewed.nf` [maniac_poisson] DSL2 - revision: b4f24dc9da
executor > local (3)
[c0/db76b3] PROCESS_FILES (3) [100%] 3 of 3 ✔
Channel content: [sample1, file1.txt]
Channel content: [sample2, file2.txt]
Channel content: [sample3, file3.txt]
After mapping: sample1
After mapping: sample2
After mapping: sample3
Sprawdź kod¶
Przyjrzyjmy się bad_channel_shape_viewed.nf, aby zobaczyć, jak używane jest .view():
Napraw kod¶
Aby uniknąć nadmiernego używania operacji .view() w przyszłości do rozumienia zawartości kanałów, warto dodać komentarze:
| bad_channel_shape_viewed.nf (with comments) | |
|---|---|
Stanie się to coraz ważniejsze w miarę jak Twoje workflow'y będą rosnąć w złożoności, a struktura kanałów stanie się mniej przejrzysta.
Uruchom pipeline¶
Wyjście polecenia
N E X T F L O W ~ version 25.10.2
Launching `bad_channel_shape_viewed.nf` [marvelous_koch] DSL2 - revision: 03e79cdbad
executor > local (3)
[ff/d67cec] PROCESS_FILES (2) | 3 of 3 ✔
Channel content: [sample1, file1.txt]
Channel content: [sample2, file2.txt]
Channel content: [sample3, file3.txt]
After mapping: sample1
After mapping: sample2
After mapping: sample3
Podsumowanie¶
Wiele błędów struktury kanałów można stworzyć przy użyciu prawidłowej składni Nextflow. Możesz je debugować, rozumiejąc przepływ danych, używając operatorów .view() do inspekcji i rozpoznając wzorce komunikatów o błędach, takie jak nawiasy kwadratowe wskazujące na nieoczekiwane struktury krotek.
Co dalej?¶
Naucz się o błędach tworzonych przez definicje procesów.
3. Błędy struktury procesów¶
Większość błędów związanych z procesami dotyczy pomyłek w formułowaniu polecenia lub problemów z oprogramowaniem. Podobnie jak w przypadku problemów z kanałami, możesz jednak popełniać błędy w definicji procesu, które nie kwalifikują się jako błędy składni, ale spowodują błędy w czasie wykonania.
3.1. Brakujące pliki wyjściowe¶
Częstym błędem przy pisaniu procesów jest stworzenie niezgodności między tym, czego oczekuje proces, a tym, co jest generowane.
Uruchom pipeline¶
Wyjście polecenia
N E X T F L O W ~ version 25.10.2
Launching `missing_output.nf` [zen_stone] DSL2 - revision: 37ff61f926
executor > local (3)
executor > local (3)
[fd/2642e9] process > PROCESS_FILES (2) [ 66%] 2 of 3, failed: 2
ERROR ~ Error executing process > 'PROCESS_FILES (3)'
Caused by:
Missing output file(s) `sample3.txt` expected by process `PROCESS_FILES (3)`
Command executed:
echo "Processing sample3" > sample3_output.txt
Command exit status:
0
Command output:
(empty)
Work dir:
/workspaces/training/side-quests/debugging/work/02/9604d49fb8200a74d737c72a6c98ed
Tip: when you have fixed the problem you can continue the execution adding the option `-resume` to the run command line
-- Check '.nextflow.log' file for details
Sprawdź kod¶
Komunikat o błędzie wskazuje, że proces oczekiwał pliku wyjściowego o nazwie sample3.txt, ale skrypt faktycznie tworzy sample3_output.txt. Przyjrzyjmy się definicji procesu w missing_output.nf:
| missing_output.nf | |
|---|---|
Widać niezgodność między nazwą pliku wyjściowego w bloku output: a tą użytą w skrypcie. Powoduje to błąd procesu. Jeśli napotkasz taki błąd, wróć i sprawdź, czy wyjścia są zgodne między definicją procesu a blokiem output.
Jeśli problem nadal nie jest jasny, sprawdź sam katalog roboczy, aby zidentyfikować faktycznie utworzone pliki wyjściowe:
W tym przykładzie pokazałoby nam to, że sufiks _output jest włączany do nazwy pliku wyjściowego, wbrew naszej definicji output:.
Napraw kod¶
Napraw niezgodność, ujednolicając nazwę pliku wyjściowego:
Uruchom pipeline¶
Wyjście polecenia
3.2. Brakujące oprogramowanie¶
Inną klasą błędów są pomyłki w dostarczaniu oprogramowania. missing_software.nf to składniowo poprawny workflow, ale zależy od zewnętrznego oprogramowania dostarczającego polecenie cowpy, którego używa.
Uruchom pipeline¶
Wyjście polecenia
ERROR ~ Error executing process > 'PROCESS_FILES (3)'
Caused by:
Process `PROCESS_FILES (3)` terminated with an error exit status (127)
Command executed:
cowpy sample3 > sample3_output.txt
Command exit status:
127
Command output:
(empty)
Command error:
.command.sh: line 2: cowpy: command not found
Work dir:
/workspaces/training/side-quests/debugging/work/82/42a5bfb60c9c6ee63ebdbc2d51aa6e
Tip: you can try to figure out what's wrong by changing to the process work directory and showing the script file named `.command.sh`
-- Check '.nextflow.log' file for details
Proces nie ma dostępu do polecenia, które określamy. Czasami dzieje się tak, ponieważ skrypt jest obecny w katalogu bin workflow'u, ale nie został uczyniony wykonywalnym. Innym razem oprogramowanie nie jest zainstalowane w kontenerze lub środowisku, w którym działa workflow.
Sprawdź kod¶
Zwróć uwagę na kod wyjścia 127 — mówi Ci dokładnie o problemie. Przyjrzyjmy się missing_software.nf:
| missing_software.nf | |
|---|---|
Napraw kod¶
Byliśmy tu trochę nieuczciwi — w kodzie tak naprawdę nie ma nic złego. Wystarczy określić niezbędną konfigurację, aby uruchomić proces w sposób zapewniający dostęp do danego polecenia. W tym przypadku proces ma definicję kontenera, więc wystarczy uruchomić workflow z włączonym Docker.
Uruchom pipeline¶
Przygotowaliśmy dla Ciebie profil Docker w nextflow.config, więc możesz uruchomić workflow za pomocą:
Wyjście polecenia
Uwaga
Aby dowiedzieć się więcej o tym, jak Nextflow używa kontenerów, zobacz Hello Nextflow
3.3. Nieprawidłowa konfiguracja zasobów¶
W środowisku produkcyjnym będziesz konfigurować zasoby dla swoich procesów. Na przykład memory definiuje maksymalną ilość pamięci dostępną dla procesu — jeśli ją przekroczy, harmonogram zazwyczaj zabija proces i zwraca kod wyjścia 137. Nie możemy tego zademonstrować tutaj, ponieważ używamy executora local, ale możemy pokazać coś podobnego z time.
Uruchom pipeline¶
bad_resources.nf ma konfigurację procesu z nierealistycznym limitem czasu wynoszącym 1 milisekundę:
Wyjście polecenia
N E X T F L O W ~ version 25.10.2
Launching `bad_resources.nf` [disturbed_elion] DSL2 - revision: 27d2066e86
executor > local (3)
[c0/ded8e1] PROCESS_FILES (3) | 0 of 3 ✘
ERROR ~ Error executing process > 'PROCESS_FILES (2)'
Caused by:
Process exceeded running time limit (1ms)
Command executed:
cowpy sample2 > sample2_output.txt
Command exit status:
-
Command output:
(empty)
Work dir:
/workspaces/training/side-quests/debugging/work/53/f0a4cc56d6b3dc2a6754ff326f1349
Container:
community.wave.seqera.io/library/cowpy:1.1.5--3db457ae1977a273
Tip: you can replicate the issue by changing to the process work dir and entering the command `bash .command.run`
-- Check '.nextflow.log' file for details
Sprawdź kod¶
Przyjrzyjmy się bad_resources.nf:
| bad_resources.nf | |
|---|---|
Wiemy, że proces zajmie więcej niż sekundę (dodaliśmy sleep, aby mieć pewność), ale jest ustawiony na przekroczenie limitu czasu po 1 milisekundzie. Ktoś był trochę nierealistyczny w swojej konfiguracji!
Napraw kod¶
Zwiększ limit czasu do realistycznej wartości:
| bad_resources.nf | |
|---|---|
Uruchom pipeline¶
Wyjście polecenia
Jeśli będziesz uważnie czytać komunikaty o błędach, takie awarie nie powinny Cię długo zastanawiać. Upewnij się jednak, że rozumiesz wymagania zasobowe uruchamianych poleceń, aby móc odpowiednio skonfigurować dyrektywy zasobów.
3.4. Techniki debugowania procesów¶
Gdy procesy zawodzą lub zachowują się nieoczekiwanie, potrzebujesz systematycznych technik do zbadania, co poszło nie tak. Katalog roboczy zawiera wszystkie informacje potrzebne do debugowania wykonania procesu.
Używanie inspekcji katalogu roboczego¶
Najpotężniejszym narzędziem debugowania procesów jest badanie katalogu roboczego. Gdy proces zawodzi, Nextflow tworzy katalog roboczy dla tego konkretnego wykonania procesu, zawierający wszystkie pliki potrzebne do zrozumienia, co się stało.
Uruchom pipeline¶
Użyjmy przykładu missing_output.nf z wcześniejszego, aby zademonstrować inspekcję katalogu roboczego (wygeneruj ponownie niezgodność nazw plików wyjściowych, jeśli potrzebujesz):
Wyjście polecenia
N E X T F L O W ~ version 25.10.2
Launching `missing_output.nf` [irreverent_payne] DSL2 - revision: 3d5117f7e2
executor > local (3)
[5d/d544a4] PROCESS_FILES (2) | 0 of 3 ✘
ERROR ~ Error executing process > 'PROCESS_FILES (1)'
Caused by:
Missing output file(s) `sample1.txt` expected by process `PROCESS_FILES (1)`
Command executed:
echo "Processing sample1" > sample1_output.txt
Command exit status:
0
Command output:
(empty)
Work dir:
/workspaces/training/side-quests/debugging/work/1e/2011154d0b0f001cd383d7364b5244
Tip: you can replicate the issue by changing to the process work dir and entering the command `bash .command.run`
-- Check '.nextflow.log' file for details
Sprawdź katalog roboczy¶
Gdy otrzymasz ten błąd, katalog roboczy zawiera wszystkie informacje do debugowania. Znajdź ścieżkę katalogu roboczego z komunikatu o błędzie i sprawdź jego zawartość:
Następnie możesz zbadać kluczowe pliki:
Sprawdź skrypt polecenia¶
Plik .command.sh pokazuje dokładnie, jakie polecenie zostało wykonane:
Ujawnia to:
- Podstawianie zmiennych: Czy zmienne Nextflow zostały prawidłowo rozwinięte
- Ścieżki plików: Czy pliki wejściowe zostały prawidłowo zlokalizowane
- Struktura polecenia: Czy składnia skryptu jest poprawna
Typowe problemy do sprawdzenia:
- Brakujące cudzysłowy: Zmienne zawierające spacje wymagają odpowiedniego cytowania
- Nieprawidłowe ścieżki plików: Pliki wejściowe, które nie istnieją lub są w złych lokalizacjach
- Nieprawidłowe nazwy zmiennych: Literówki w odwołaniach do zmiennych
- Brakująca konfiguracja środowiska: Polecenia zależne od określonych środowisk
Sprawdź wyjście błędów¶
Plik .command.err zawiera faktyczne komunikaty o błędach:
Ten plik pokaże:
- Kody wyjścia: 127 (polecenie nie znalezione), 137 (zabity), itp.
- Błędy uprawnień: Problemy z dostępem do plików
- Błędy oprogramowania: Komunikaty o błędach specyficzne dla aplikacji
- Błędy zasobów: Przekroczenie limitu pamięci/czasu
Sprawdź standardowe wyjście¶
Plik .command.out pokazuje, co wyprodukowało Twoje polecenie:
Pomaga to zweryfikować:
- Oczekiwane wyjście: Czy polecenie wyprodukowało właściwe wyniki
- Częściowe wykonanie: Czy polecenie zaczęło się, ale nie powiodło się w połowie
- Informacje diagnostyczne: Wszelkie dane diagnostyczne z Twojego skryptu
Sprawdź kod wyjścia¶
Plik .exitcode zawiera kod wyjścia procesu:
Typowe kody wyjścia i ich znaczenie:
- Kod wyjścia 127: Polecenie nie znalezione — sprawdź instalację oprogramowania
- Kod wyjścia 137: Proces zabity — sprawdź limity pamięci/czasu
Sprawdź istnienie plików¶
Gdy procesy zawodzą z powodu brakujących plików wyjściowych, sprawdź, jakie pliki zostały faktycznie utworzone:
Pomaga to zidentyfikować:
- Niezgodności nazw plików: Pliki wyjściowe o innych nazwach niż oczekiwano
- Problemy z uprawnieniami: Pliki, których nie można było utworzyć
- Problemy ze ścieżkami: Pliki utworzone w złych katalogach
We wcześniejszym przykładzie potwierdziło nam to, że oczekiwany sample3.txt nie był obecny, ale sample3_output.txt był:
Podsumowanie¶
Debugowanie procesów wymaga badania katalogów roboczych w celu zrozumienia, co poszło nie tak. Kluczowe pliki to .command.sh (wykonany skrypt), .command.err (komunikaty o błędach) i .command.out (standardowe wyjście). Kody wyjścia takie jak 127 (polecenie nie znalezione) i 137 (proces zabity) dostarczają natychmiastowych wskazówek diagnostycznych dotyczących rodzaju awarii.
Co dalej?¶
Poznaj wbudowane narzędzia debugowania Nextflow i systematyczne podejścia do rozwiązywania problemów.
4. Wbudowane narzędzia debugowania i zaawansowane techniki¶
Nextflow udostępnia kilka potężnych wbudowanych narzędzi do debugowania i analizowania wykonania workflow'u. Pomagają one zrozumieć, co poszło nie tak, gdzie to się stało i jak to efektywnie naprawić.
4.1. Wyjście procesu w czasie rzeczywistym¶
Czasami musisz zobaczyć, co dzieje się wewnątrz uruchomionych procesów. Możesz włączyć wyjście procesu w czasie rzeczywistym, które pokazuje dokładnie, co robi każde zadanie podczas wykonywania.
Uruchom pipeline¶
bad_channel_shape_viewed.nf z naszych wcześniejszych przykładów drukował zawartość kanału za pomocą .view(), ale możemy również użyć dyrektywy debug, aby wyświetlać zmienne z wnętrza samego procesu — demonstrujemy to w bad_channel_shape_viewed_debug.nf. Uruchom workflow:
Wyjście polecenia
N E X T F L O W ~ version 25.10.2
Launching `bad_channel_shape_viewed_debug.nf` [agitated_crick] DSL2 - revision: ea3676d9ec
executor > local (3)
[c6/2dac51] process > PROCESS_FILES (3) [100%] 3 of 3 ✔
Channel content: [sample1, file1.txt]
Channel content: [sample2, file2.txt]
Channel content: [sample3, file3.txt]
After mapping: sample1
After mapping: sample2
After mapping: sample3
Sample name inside process is sample2
Sample name inside process is sample1
Sample name inside process is sample3
Sprawdź kod¶
Przyjrzyjmy się bad_channel_shape_viewed_debug.nf, aby zobaczyć, jak działa dyrektywa debug:
| bad_channel_shape_viewed_debug.nf | |
|---|---|
Dyrektywa debug może być szybkim i wygodnym sposobem na zrozumienie środowiska procesu.
4.2. Tryb podglądu¶
Czasami chcesz wykryć problemy zanim uruchomią się jakiekolwiek procesy. Nextflow udostępnia flagę do tego rodzaju proaktywnego debugowania: -preview.
Uruchom pipeline¶
Tryb podglądu pozwala testować logikę workflow'u bez wykonywania poleceń. Może być bardzo przydatny do szybkiego sprawdzania struktury workflow'u i upewniania się, że procesy są prawidłowo połączone, bez uruchamiania żadnych rzeczywistych poleceń.
Uwaga
Jeśli wcześniej naprawiłeś/naprawiłaś bad_syntax.nf, przywróć błąd składni, usuwając nawias zamykający po bloku skryptu przed uruchomieniem tego polecenia.
Uruchom to polecenie:
Wyjście polecenia
Tryb podglądu jest szczególnie przydatny do wczesnego wykrywania błędów składni bez uruchamiania żadnych procesów. Weryfikuje strukturę workflow'u i połączenia procesów przed wykonaniem.
4.3. Stub running do testowania logiki¶
Czasami błędy są trudne do debugowania, ponieważ polecenia trwają zbyt długo, wymagają specjalnego oprogramowania lub zawodzą z złożonych powodów. Stub running pozwala testować logikę workflow'u bez wykonywania rzeczywistych poleceń.
Uruchom pipeline¶
Podczas tworzenia procesu Nextflow możesz użyć dyrektywy stub, aby zdefiniować „fikcyjne" polecenia generujące wyjścia o właściwej formie bez uruchamiania rzeczywistego polecenia. Takie podejście jest szczególnie wartościowe, gdy chcesz zweryfikować poprawność logiki workflow'u przed zmierzeniem się ze złożonością rzeczywistego oprogramowania.
Pamiętasz nasz missing_software.nf z wcześniejszego? Ten, w którym brakowało oprogramowania uniemożliwiającego uruchomienie workflow'u, dopóki nie dodaliśmy -profile docker? missing_software_with_stub.nf to bardzo podobny workflow. Jeśli uruchomimy go w ten sam sposób, wygenerujemy ten sam błąd:
Wyjście polecenia
ERROR ~ Error executing process > 'PROCESS_FILES (3)'
Caused by:
Process `PROCESS_FILES (3)` terminated with an error exit status (127)
Command executed:
cowpy sample3 > sample3_output.txt
Command exit status:
127
Command output:
(empty)
Command error:
.command.sh: line 2: cowpy: command not found
Work dir:
/workspaces/training/side-quests/debugging/work/82/42a5bfb60c9c6ee63ebdbc2d51aa6e
Tip: you can try to figure out what's wrong by changing to the process work directory and showing the script file named `.command.sh`
-- Check '.nextflow.log' file for details
Jednak ten workflow nie wygeneruje błędów, jeśli uruchomimy go z -stub-run, nawet bez profilu docker:
Wyjście polecenia
Sprawdź kod¶
Przyjrzyjmy się missing_software_with_stub.nf:
| missing_software.nf (with stub) | |
|---|---|
W porównaniu z missing_software.nf, ten proces ma dyrektywę stub: określającą polecenie, które ma być użyte zamiast tego z script:, gdy Nextflow jest uruchamiany w trybie stub.
Polecenie touch, którego tu używamy, nie zależy od żadnego oprogramowania ani odpowiednich wejść i będzie działać w każdej sytuacji, pozwalając nam debugować logikę workflow'u bez martwienia się o wewnętrzne działanie procesu.
Stub running pomaga debugować:
- Strukturę kanałów i przepływ danych
- Połączenia procesów i zależności
- Propagację parametrów
- Logikę workflow'u bez zależności od oprogramowania
4.4. Systematyczne podejście do debugowania¶
Teraz, gdy poznałeś/poznałaś poszczególne techniki debugowania — od katalogów roboczych po tryb podglądu, stub running i monitorowanie zasobów — połączmy je w systematyczną metodologię. Ustrukturyzowane podejście zapobiega przytłoczeniu złożonymi błędami i zapewnia, że nie przeoczysz ważnych wskazówek.
Ta metodologia łączy wszystkie omówione narzędzia w efektywny workflow:
Czterofazowa metoda debugowania:
Faza 1: Rozwiązywanie błędów składni (5 minut)
- Sprawdź czerwone podkreślenia w VSCode lub Twoim IDE
- Uruchom
nextflow run workflow.nf -preview, aby zidentyfikować problemy ze składnią - Napraw wszystkie błędy składni (brakujące nawiasy klamrowe, końcowe przecinki itp.)
- Upewnij się, że workflow parsuje się pomyślnie przed kontynuowaniem
Faza 2: Szybka ocena (5 minut)
- Uważnie przeczytaj komunikaty o błędach w czasie wykonania
- Sprawdź, czy to błąd wykonania, logiki czy zasobów
- Użyj trybu podglądu do testowania podstawowej logiki workflow'u
Faza 3: Szczegółowe badanie (15–30 minut)
- Znajdź katalog roboczy nieudanego zadania
- Zbadaj pliki dziennika
- Dodaj operatory
.view()do inspekcji kanałów - Użyj
-stub-rundo testowania logiki workflow'u bez wykonania
Faza 4: Naprawa i walidacja (15 minut)
- Wprowadź minimalne, ukierunkowane poprawki
- Przetestuj z resume:
nextflow run workflow.nf -resume - Zweryfikuj kompletne wykonanie workflow'u
Używanie resume do efektywnego debugowania
Po zidentyfikowaniu problemu potrzebujesz efektywnego sposobu testowania poprawek bez marnowania czasu na ponowne uruchamianie pomyślnych części workflow'u. Funkcjonalność -resume Nextflow jest nieoceniona przy debugowaniu.
Zetknąłeś/zetknęłaś się z -resume podczas pracy z Hello Nextflow, i ważne jest, abyś z niego korzystał/korzystała podczas debugowania, aby zaoszczędzić czas oczekiwania na uruchomienie procesów poprzedzających problematyczny.
Strategia debugowania z resume:
- Uruchom workflow do momentu awarii
- Zbadaj katalog roboczy nieudanego zadania
- Napraw konkretny problem
- Wznów, aby przetestować tylko poprawkę
- Powtarzaj, aż workflow zakończy się pomyślnie
Profil konfiguracji debugowania¶
Aby to systematyczne podejście było jeszcze bardziej efektywne, możesz utworzyć dedykowaną konfigurację debugowania, która automatycznie włącza wszystkie potrzebne narzędzia:
| nextflow.config (debug profile) | |
|---|---|
Następnie możesz uruchomić pipeline z tym profilem:
Ten profil włącza wyjście w czasie rzeczywistym, zachowuje katalogi robocze i ogranicza paralelizację dla łatwiejszego debugowania.
4.5. Praktyczne ćwiczenie debugowania¶
Czas zastosować systematyczne podejście do debugowania w praktyce. Workflow buggy_workflow.nf zawiera kilka typowych błędów reprezentujących rodzaje problemów, z którymi spotkasz się w rzeczywistym środowisku programistycznym.
Ćwiczenie
Użyj systematycznego podejścia do debugowania, aby zidentyfikować i naprawić wszystkie błędy w buggy_workflow.nf. Ten workflow próbuje przetwarzać dane próbek z pliku CSV, ale zawiera wiele celowych błędów reprezentujących typowe scenariusze debugowania.
Zacznij od uruchomienia workflow'u, aby zobaczyć pierwszy błąd:
Wyjście polecenia
N E X T F L O W ~ version 25.10.2
Launching `buggy_workflow.nf` [wise_ramanujan] DSL2 - revision: d51a8e83fd
ERROR ~ Range [11, 12) out of bounds for length 11
-- Check '.nextflow.log' file for details
Ten tajemniczy błąd wskazuje na problem parsowania wokół wierszy 11–12 w bloku params{}. Parser v2 wykrywa problemy strukturalne wcześnie.
Zastosuj czterofazową metodę debugowania, której się nauczyłeś/nauczyłaś:
Faza 1: Rozwiązywanie błędów składni
- Sprawdź czerwone podkreślenia w VSCode lub Twoim IDE
- Uruchom nextflow run workflow.nf -preview, aby zidentyfikować problemy ze składnią
- Napraw wszystkie błędy składni (brakujące nawiasy klamrowe, końcowe przecinki itp.)
- Upewnij się, że workflow parsuje się pomyślnie przed kontynuowaniem
Faza 2: Szybka ocena
- Uważnie przeczytaj komunikaty o błędach w czasie wykonania
- Zidentyfikuj, czy błędy są związane z wykonaniem, logiką czy zasobami
- Użyj trybu -preview do testowania podstawowej logiki workflow'u
Faza 3: Szczegółowe badanie
- Zbadaj katalogi robocze nieudanych zadań
- Dodaj operatory .view() do inspekcji kanałów
- Sprawdź pliki dziennika w katalogach roboczych
- Użyj -stub-run do testowania logiki workflow'u bez wykonania
Faza 4: Naprawa i walidacja
- Wprowadź ukierunkowane poprawki
- Użyj -resume do efektywnego testowania poprawek
- Zweryfikuj kompletne wykonanie workflow'u
Narzędzia debugowania do Twojej dyspozycji:
# Tryb podglądu do sprawdzania składni
nextflow run buggy_workflow.nf -preview
# Profil debug do szczegółowego wyjścia
nextflow run buggy_workflow.nf -profile debug
# Stub running do testowania logiki
nextflow run buggy_workflow.nf -stub-run
# Resume po poprawkach
nextflow run buggy_workflow.nf -resume
Rozwiązanie
buggy_workflow.nf zawiera 9 lub 10 odrębnych błędów (w zależności od sposobu liczenia) obejmujących wszystkie główne kategorie debugowania. Oto systematyczne omówienie każdego błędu i sposobu jego naprawienia.
Zacznijmy od błędów składni:
Błąd 1: Błąd składni — końcowy przecinek
Poprawka: Usuń końcowy przecinekBłąd 2: Błąd składni — brakujący nawias zamykający
Błąd 3: Błąd nazwy zmiennej
Błąd 4: Błąd niezdefiniowanej zmiennej
W tym momencie workflow uruchomi się, ale nadal będziemy otrzymywać błędy (np. Path value cannot be null w processFiles), spowodowane złą strukturą kanału.
Błąd 5: Błąd struktury kanału — nieprawidłowe wyjście map
Ale to zepsuje nasze wywołanie heavyProcess() powyżej, więc będziemy musieli użyć map, aby przekazać tylko identyfikatory próbek do tego procesu:
Błąd 6: Zła struktura kanału dla heavyProcess
Teraz docieramy dalej, ale otrzymujemy błąd No such variable: i, ponieważ nie poprzedziliśmy zmiennej Bash ukośnikiem.
Błąd 7: Błąd poprzedzania zmiennej Bash
Teraz otrzymujemy Process exceeded running time limit (1ms), więc naprawiamy limit czasu dla odpowiedniego procesu:
Błąd 8: Błąd konfiguracji zasobów
Następnie mamy błąd Missing output file(s) do rozwiązania:
Błąd 9: Niezgodność nazwy pliku wyjściowego
Pierwsze dwa procesy uruchomiły się, ale nie trzeci.
Błąd 10: Niezgodność nazwy pliku wyjściowego
Po tym cały workflow powinien działać.
Kompletny poprawiony workflow:
Omówione kategorie błędów:
- Błędy składni: Brakujące nawiasy klamrowe, końcowe przecinki, niezdefiniowane zmienne
- Błędy struktury kanałów: Nieprawidłowe kształty danych, niezdefiniowane kanały
- Błędy procesów: Niezgodności nazw plików wyjściowych, poprzedzanie zmiennych
- Błędy zasobów: Nierealistyczne limity czasu
Kluczowe lekcje debugowania:
- Uważnie czytaj komunikaty o błędach — często wskazują bezpośrednio na problem
- Używaj systematycznych podejść — naprawiaj jeden błąd na raz i testuj z
-resume - Rozumiej przepływ danych — błędy struktury kanałów są często najbardziej subtelne
- Sprawdzaj katalogi robocze — gdy procesy zawodzą, dzienniki mówią Ci dokładnie, co poszło nie tak
Podsumowanie¶
W tym side queście poznałeś/poznałaś zestaw systematycznych technik debugowania workflow'ów Nextflow. Stosowanie tych technik w swojej pracy pozwoli Ci spędzać mniej czasu na walce z komputerem, szybciej rozwiązywać problemy i chronić się przed przyszłymi błędami.
Kluczowe wzorce¶
1. Jak identyfikować i naprawiać błędy składni:
- Interpretowanie komunikatów o błędach Nextflow i lokalizowanie problemów
- Typowe błędy składni: brakujące nawiasy klamrowe, nieprawidłowe słowa kluczowe, niezdefiniowane zmienne
- Rozróżnianie między zmiennymi Nextflow (Groovy) a Bash
- Używanie funkcji rozszerzenia VS Code do wczesnego wykrywania błędów
// Brakujący nawias — szukaj czerwonych podkreśleń w IDE
process FOO {
script:
"""
echo "hello"
"""
// } <-- brakuje!
// Nieprawidłowe słowo kluczowe
inputs: // Powinno być 'input:'
// Niezdefiniowana zmienna — poprzedź ukośnikiem dla zmiennych Bash
echo "${undefined_var}" // Zmienna Nextflow (błąd jeśli niezdefiniowana)
echo "\${bash_var}" // Zmienna Bash (poprzedzona ukośnikiem)
2. Jak debugować problemy ze strukturą kanałów:
- Rozumienie kardynalności kanałów i problemów z wyczerpaniem
- Debugowanie niezgodności struktury zawartości kanałów
- Używanie operatorów
.view()do inspekcji kanałów - Rozpoznawanie wzorców błędów, takich jak nawiasy kwadratowe w wyjściu
// Inspekcja zawartości kanału
my_channel.view { "Content: $it" }
// Konwersja kanału kolejki na kanał wartości (zapobiega wyczerpaniu)
reference_ch = channel.value('ref.fa')
// lub
reference_ch = channel.of('ref.fa').first()
3. Jak rozwiązywać problemy z wykonaniem procesów:
- Diagnozowanie błędów brakujących plików wyjściowych
- Rozumienie kodów wyjścia (127 dla brakującego oprogramowania, 137 dla problemów z pamięcią)
- Badanie katalogów roboczych i plików poleceń
- Odpowiednia konfiguracja zasobów
# Sprawdź, co faktycznie zostało wykonane
cat work/ab/cdef12/.command.sh
# Sprawdź wyjście błędów
cat work/ab/cdef12/.command.err
# Kod wyjścia 127 = polecenie nie znalezione
# Kod wyjścia 137 = zabity (limit pamięci/czasu)
4. Jak używać wbudowanych narzędzi debugowania Nextflow:
- Korzystanie z trybu podglądu i debugowania w czasie rzeczywistym
- Implementacja stub running do testowania logiki
- Stosowanie resume do efektywnych cykli debugowania
- Stosowanie czterofazowej systematycznej metodologii debugowania
Szybki przewodnik po debugowaniu
Błędy składni? → Sprawdź ostrzeżenia VSCode, uruchom nextflow run workflow.nf -preview
Problemy z kanałami? → Użyj .view() do inspekcji zawartości: my_channel.view()
Awarie procesów? → Sprawdź pliki w katalogu roboczym:
.command.sh— wykonany skrypt.command.err— komunikaty o błędach.exitcode— status wyjścia (127 = polecenie nie znalezione, 137 = zabity)
Tajemnicze zachowanie? → Uruchom z -stub-run, aby przetestować logikę workflow'u
Wprowadziłeś/wprowadziłaś poprawki? → Użyj -resume, aby zaoszczędzić czas: nextflow run workflow.nf -resume
Dodatkowe zasoby¶
- Przewodnik rozwiązywania problemów Nextflow: Oficjalna dokumentacja rozwiązywania problemów
- Rozumienie kanałów Nextflow: Szczegółowe omówienie typów kanałów i ich zachowania
- Dokumentacja dyrektyw procesów: Wszystkie dostępne opcje konfiguracji procesów
- nf-test: Framework testowy dla pipeline'ów Nextflow
- Społeczność Nextflow na Slack: Uzyskaj pomoc od społeczności
W przypadku workflow'ów produkcyjnych rozważ:
- Skonfigurowanie Seqera Platform do monitorowania i debugowania na dużą skalę
- Używanie kontenerów Wave dla reprodukowalnych środowisk oprogramowania
Pamiętaj: Efektywne debugowanie to umiejętność, która doskonali się z praktyką. Systematyczna metodologia i kompleksowy zestaw narzędzi, które tu zdobyłeś/zdobyłaś, będą Ci dobrze służyć przez całą Twoją drogę z Nextflow.
Co dalej?¶
Wróć do menu Side Quests lub kliknij przycisk w prawym dolnym rogu strony, aby przejść do następnego tematu na liście.